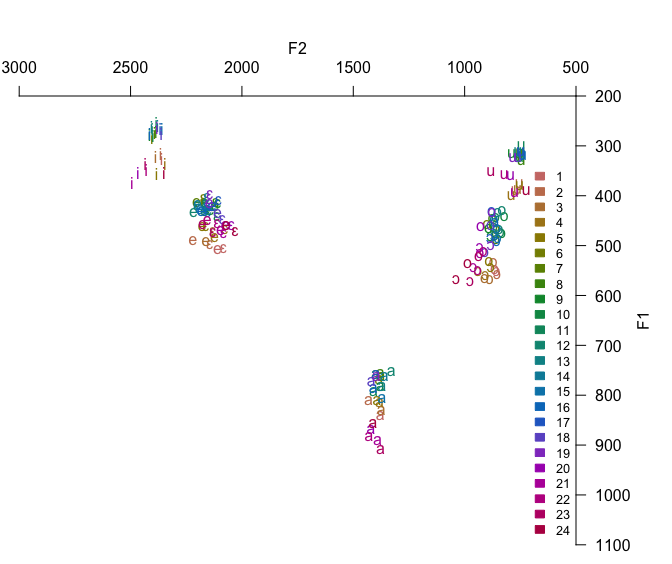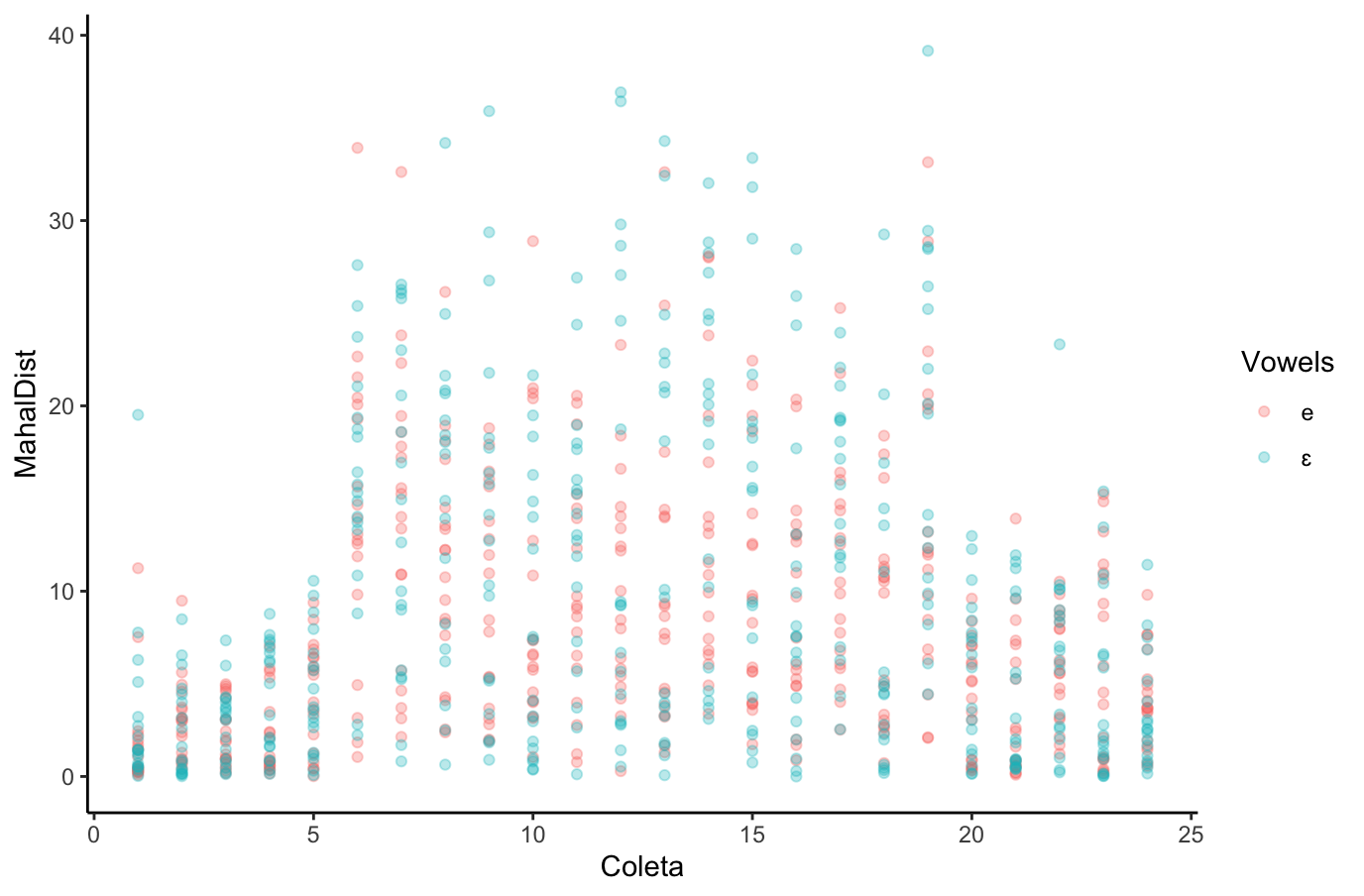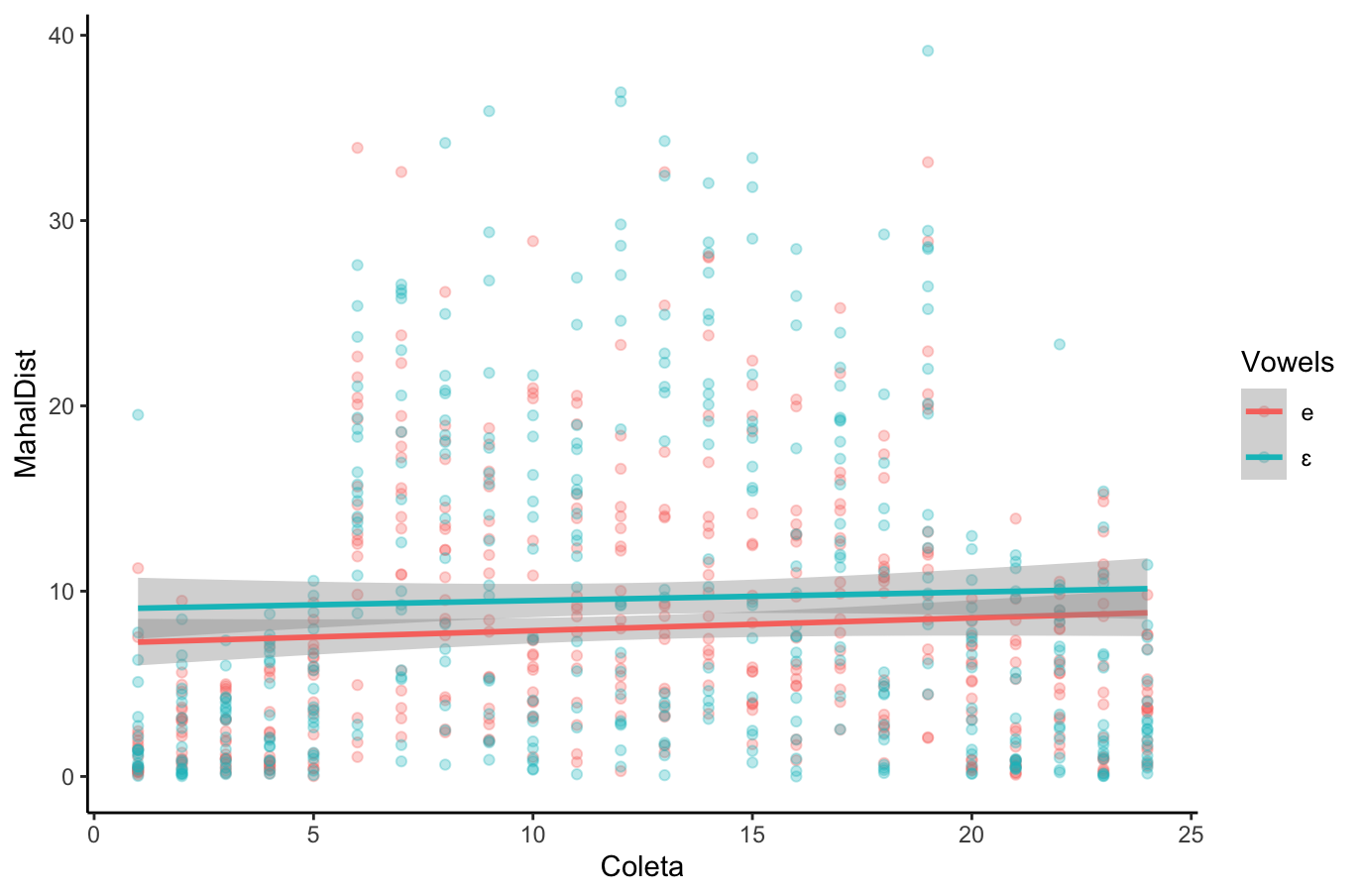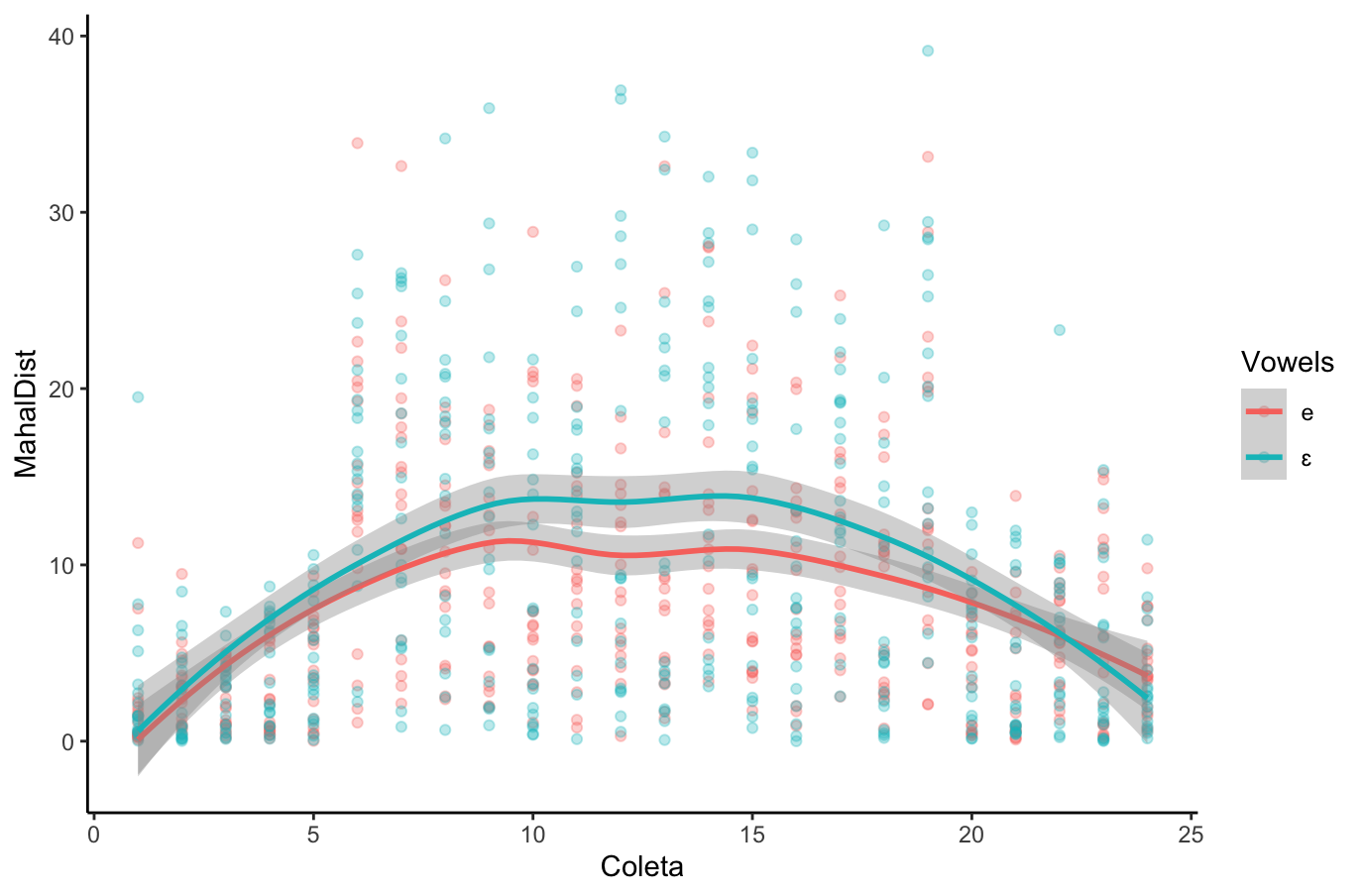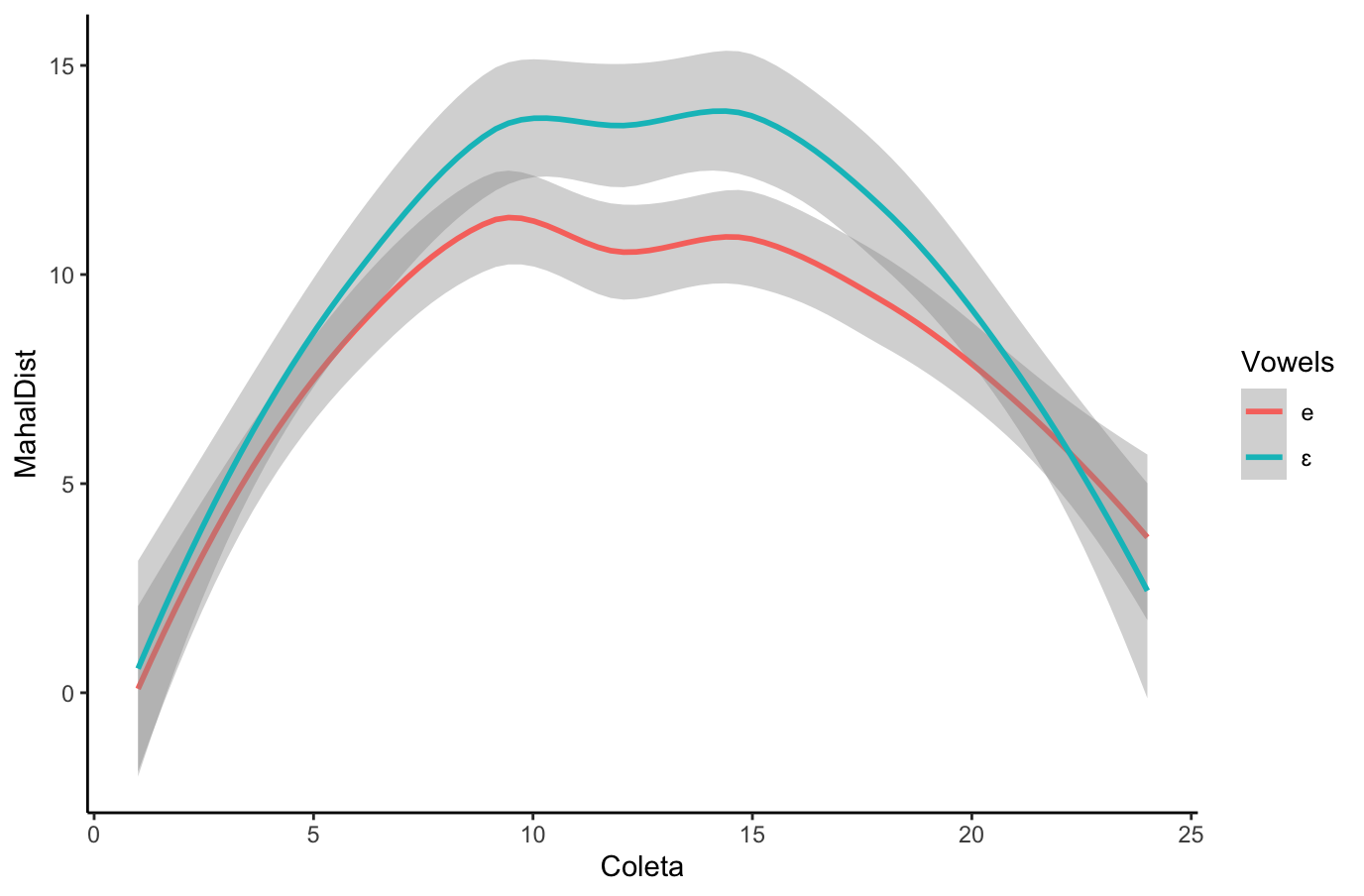
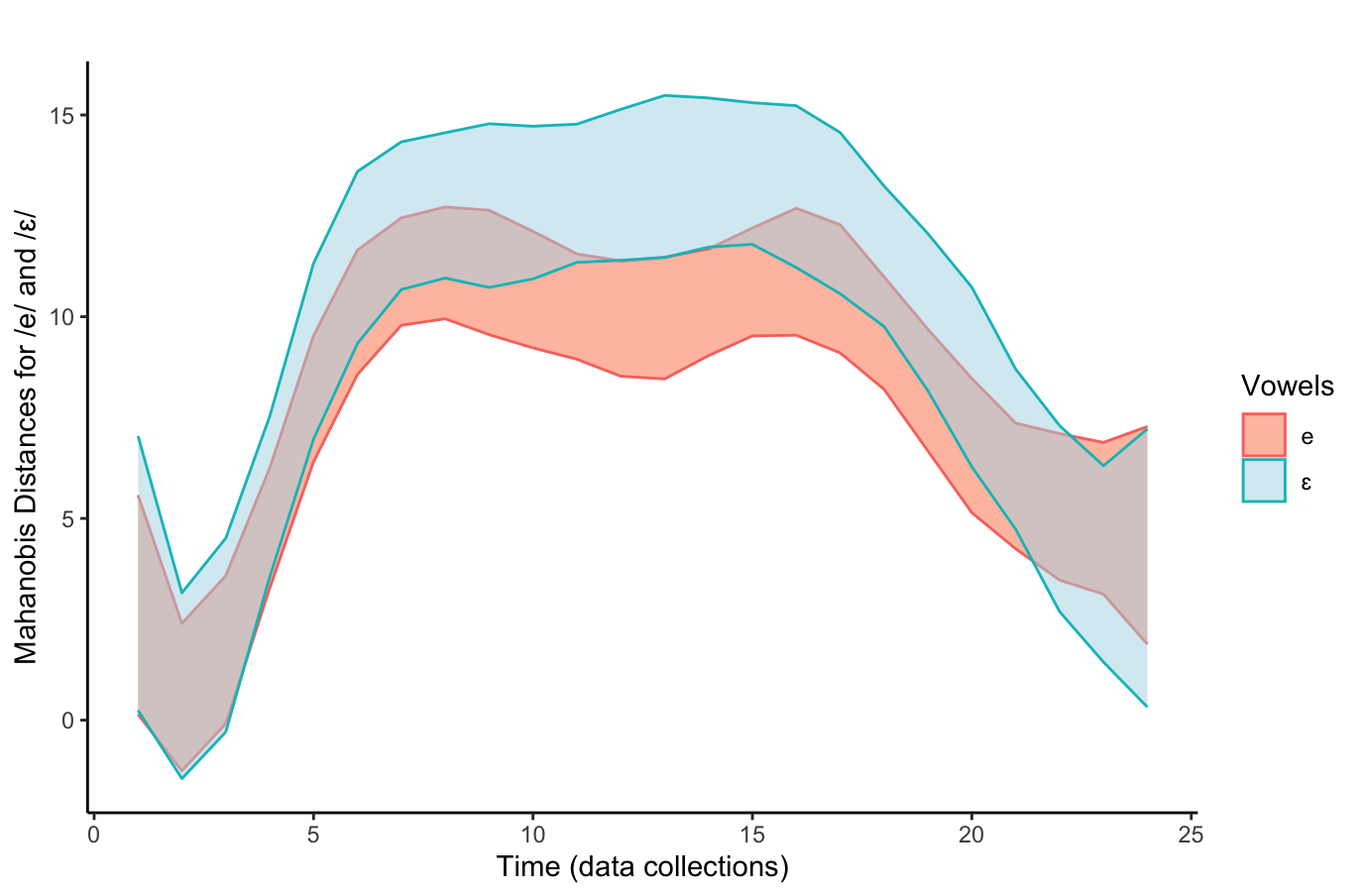
[1] 0.06660531[1] 0.04431304(na análise de dados phonéticos)
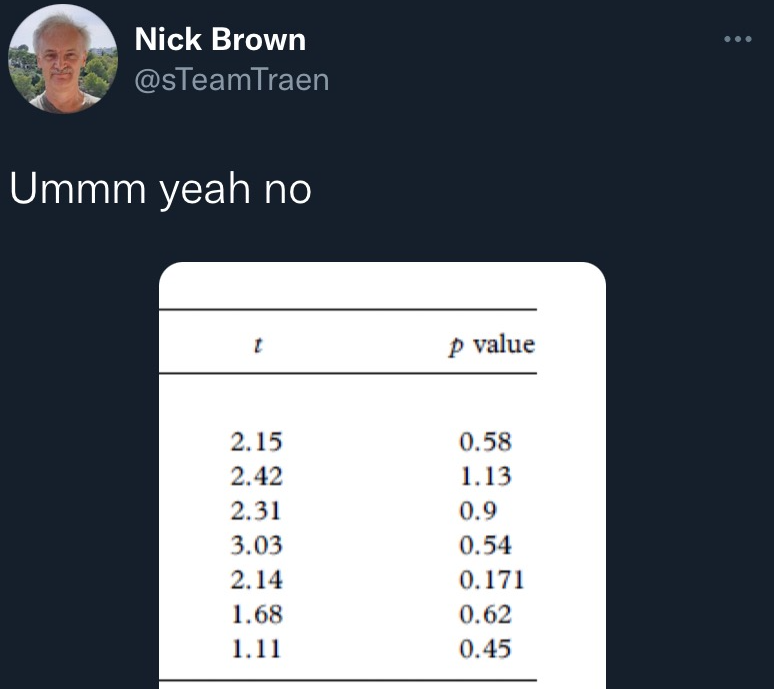
“I want to break p”
3 jogadas
6 jogadas
12 jogadas
50 jogadas
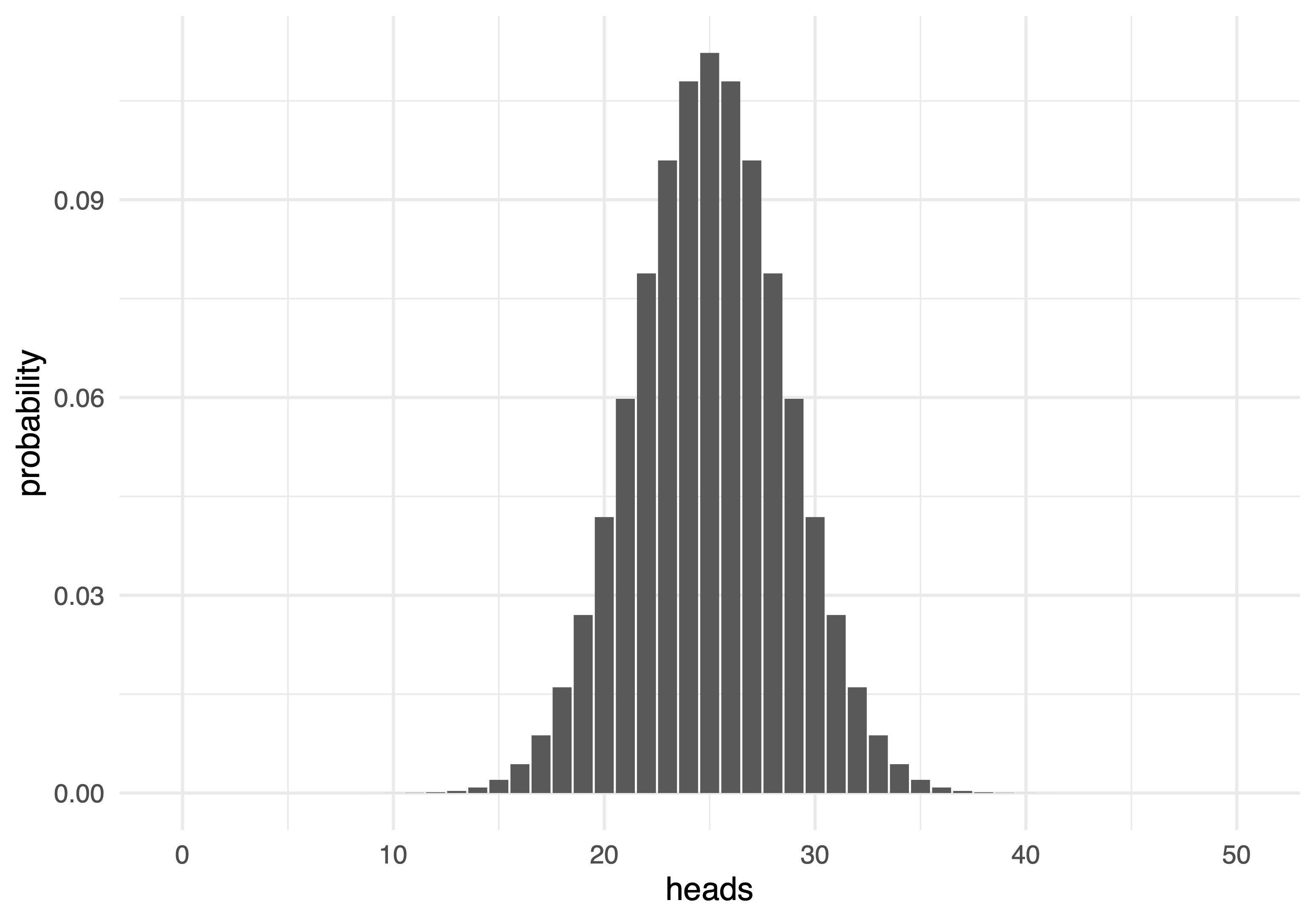
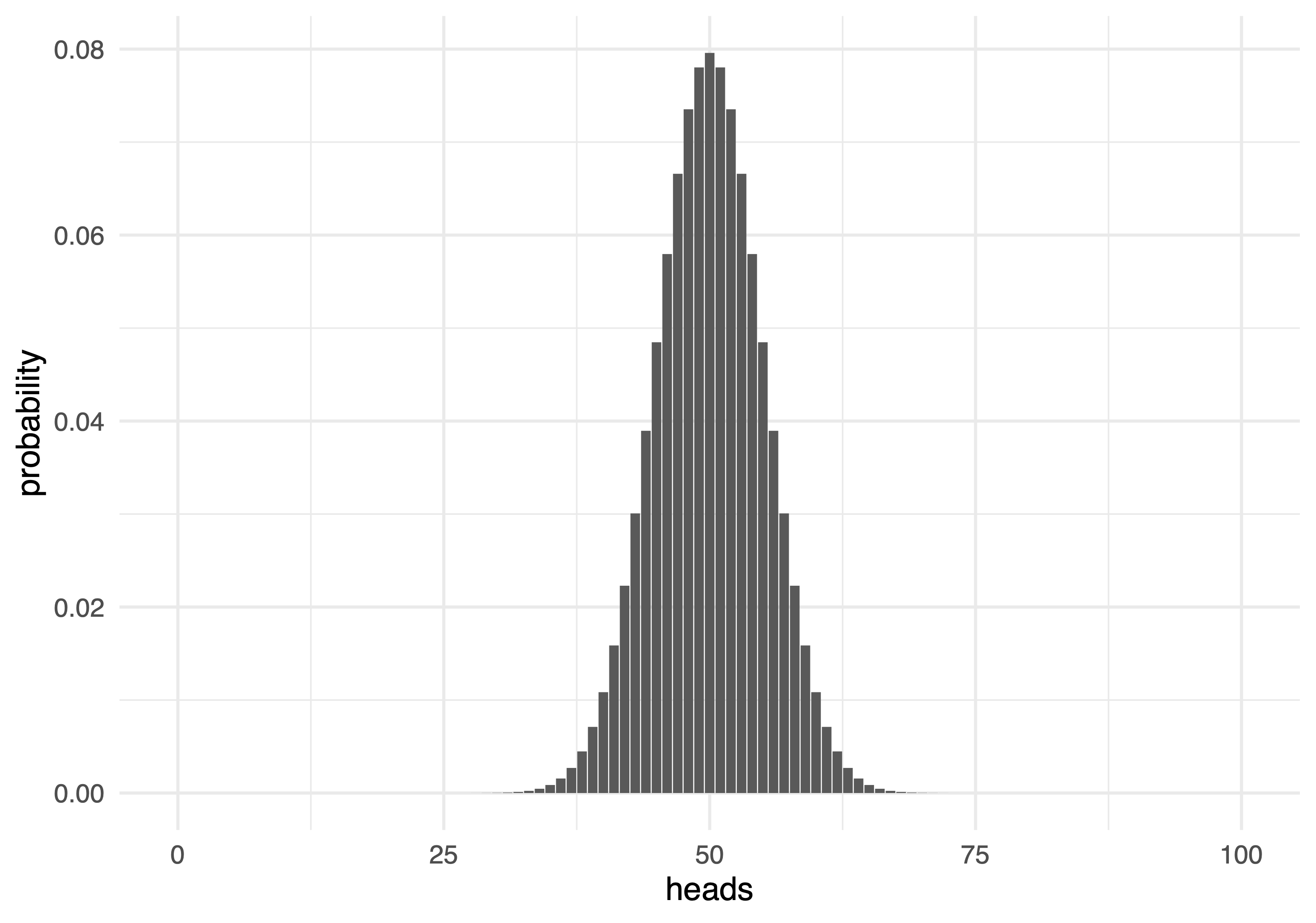
100 jogadas
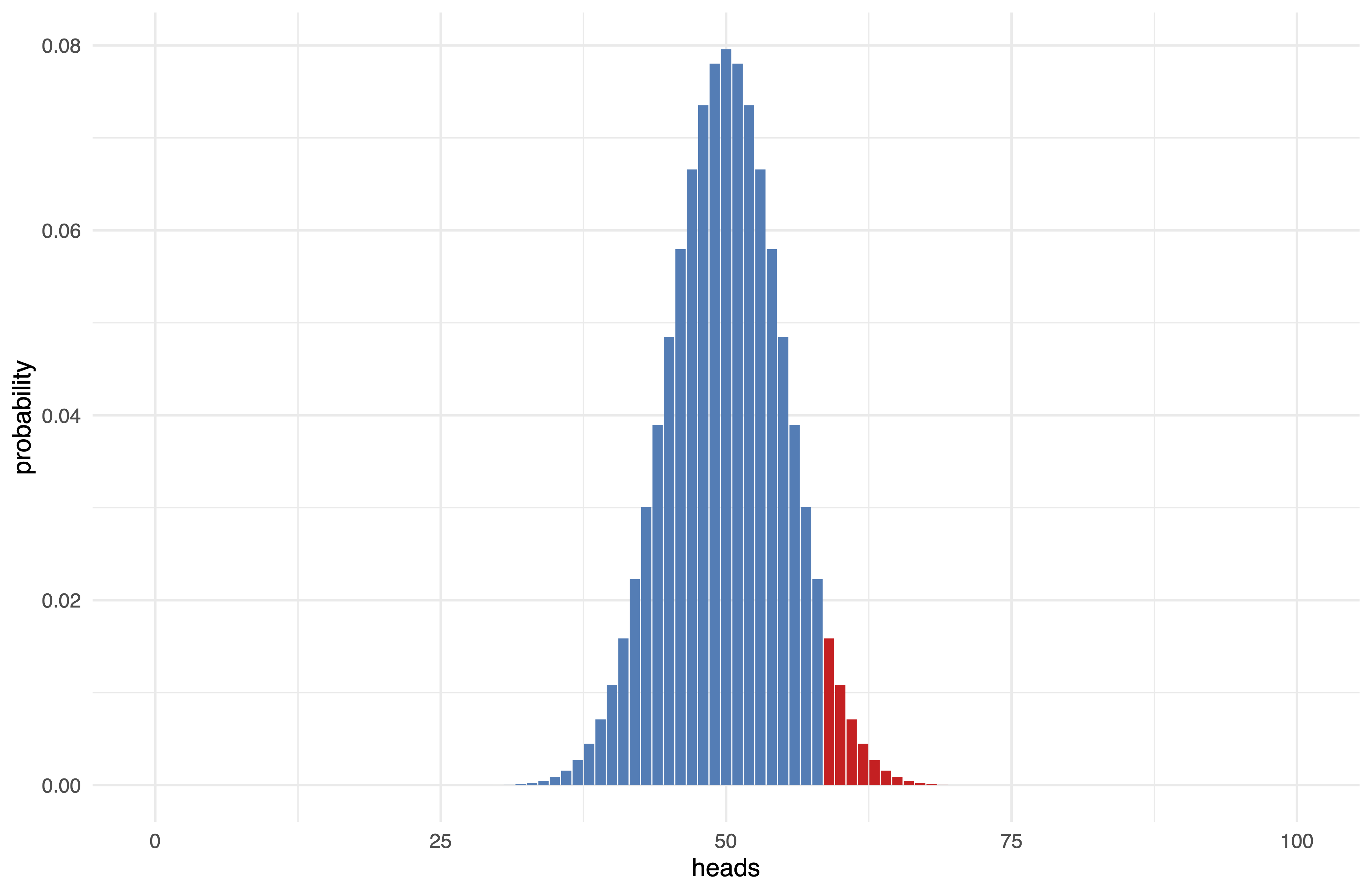
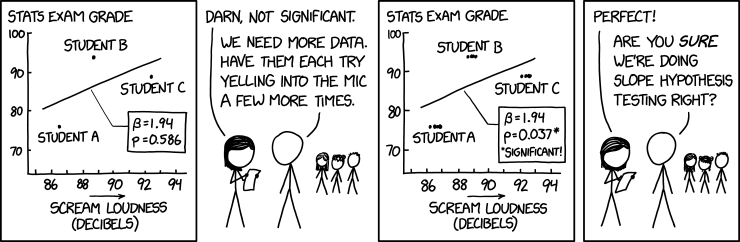
sum(dbinom(90:100, 100, 0.5))1.531645e-17 \(\rightarrow 0.000000000000001531645\%\)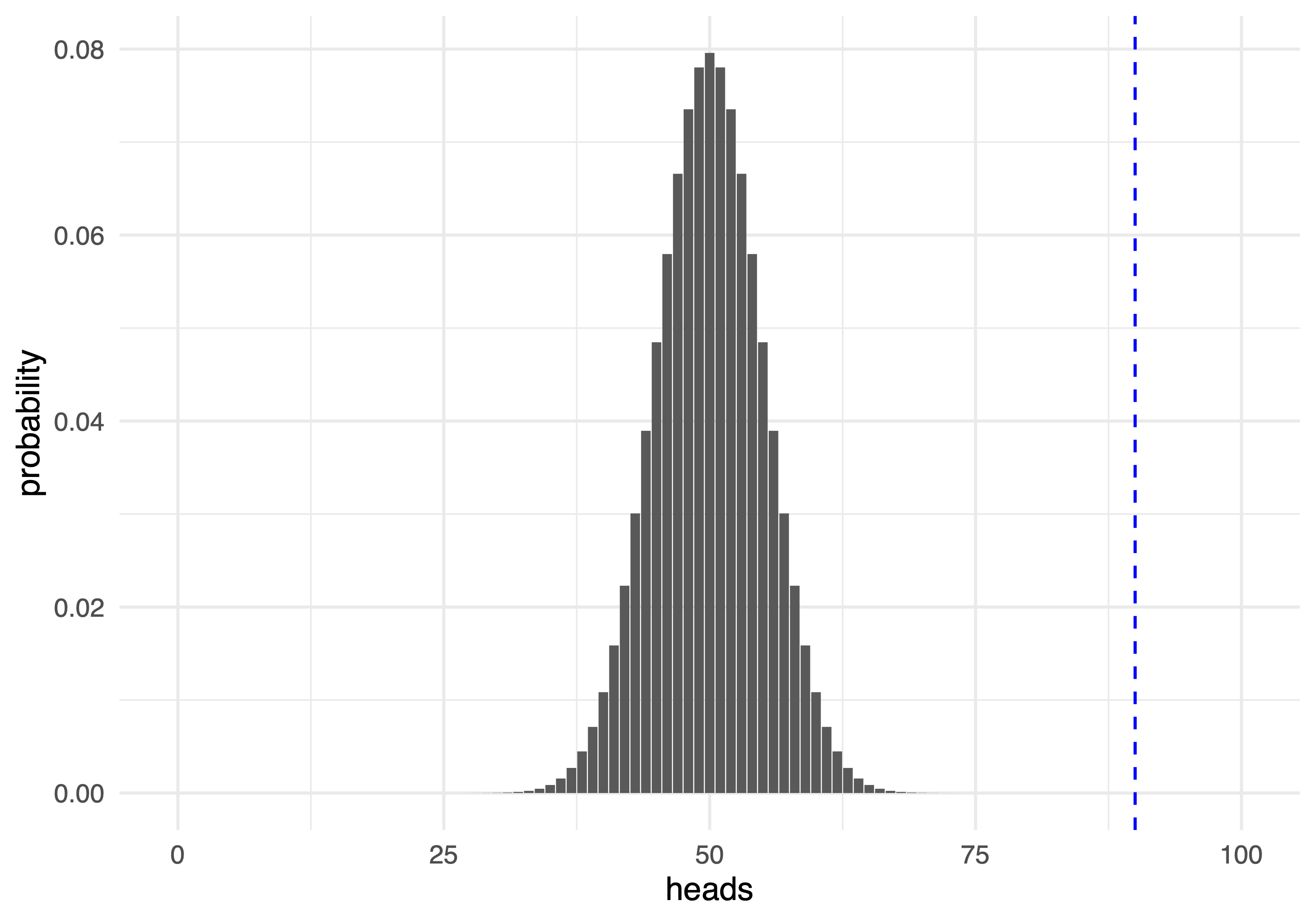
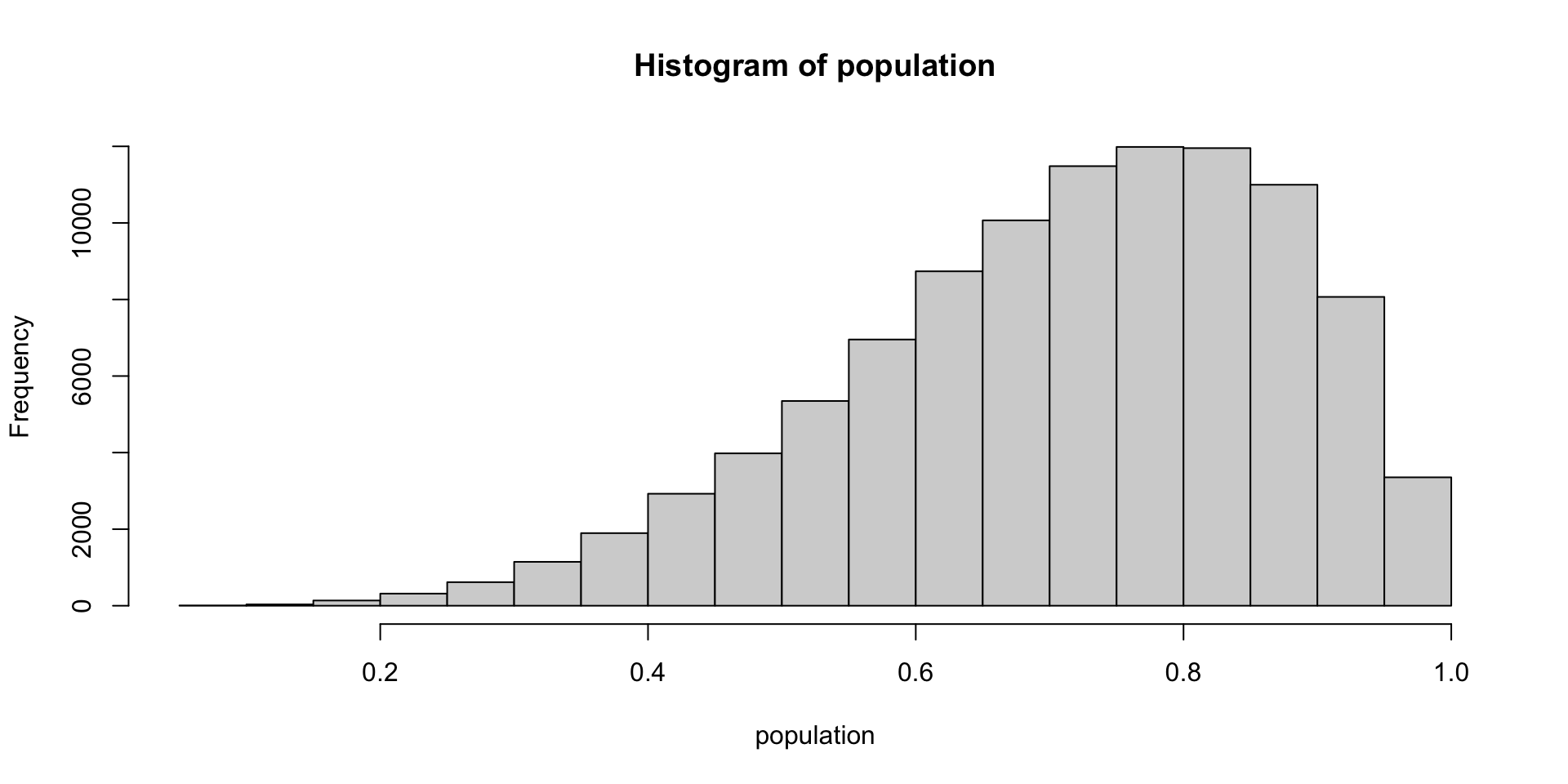
sample1 = sample(x = population, size = 20)
sample2 = sample(x = population, size = 20)
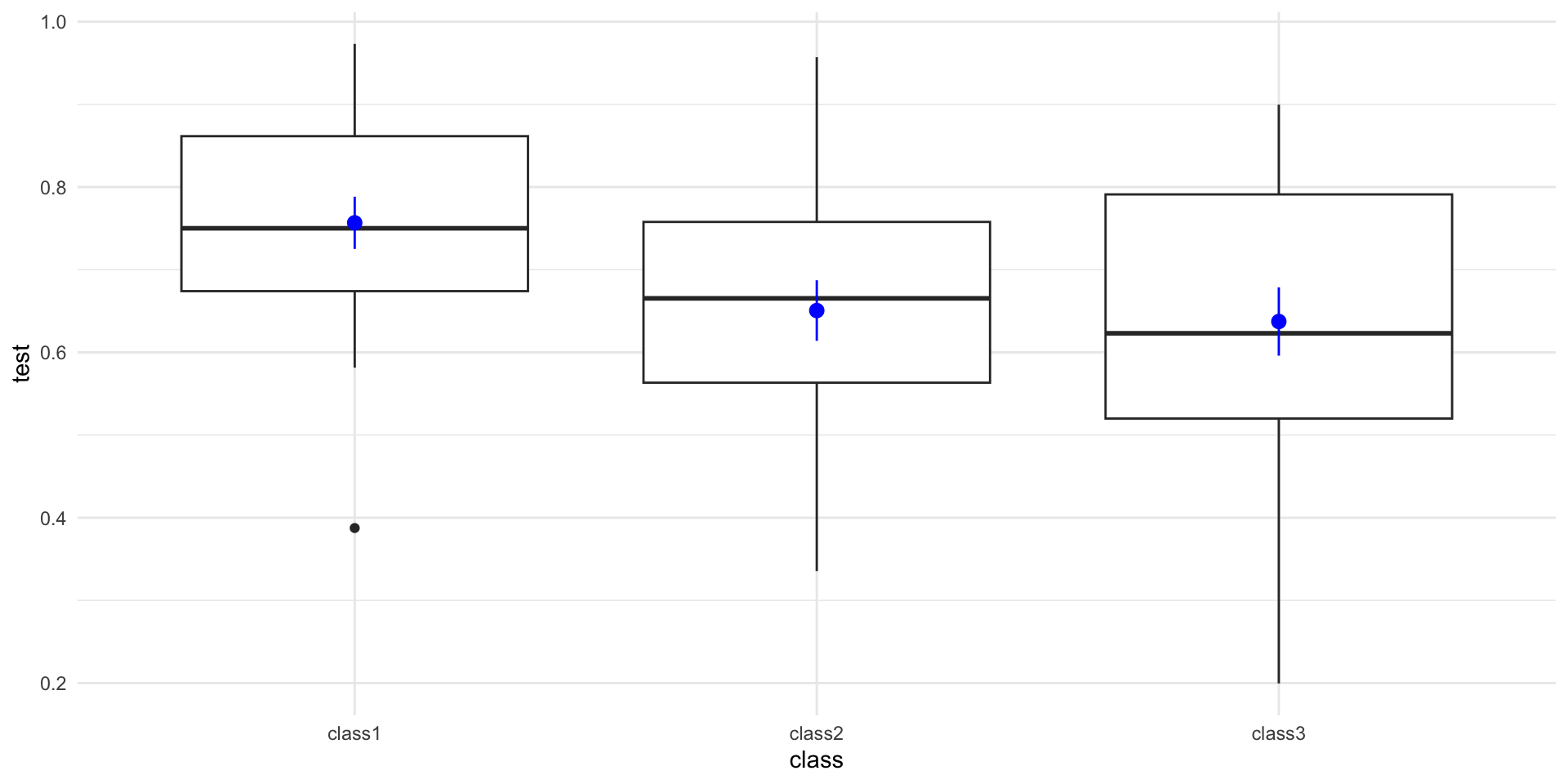
sample3 = sample(x = population, size = 20)| class | mean | SD |
|---|---|---|
| class1 | 0.76 | 0.14 |
| class2 | 0.65 | 0.16 |
| class3 | 0.64 | 0.18 |
sample4 = sample(x = population, size = 322)
sample5 = sample(x = population, size = 322)
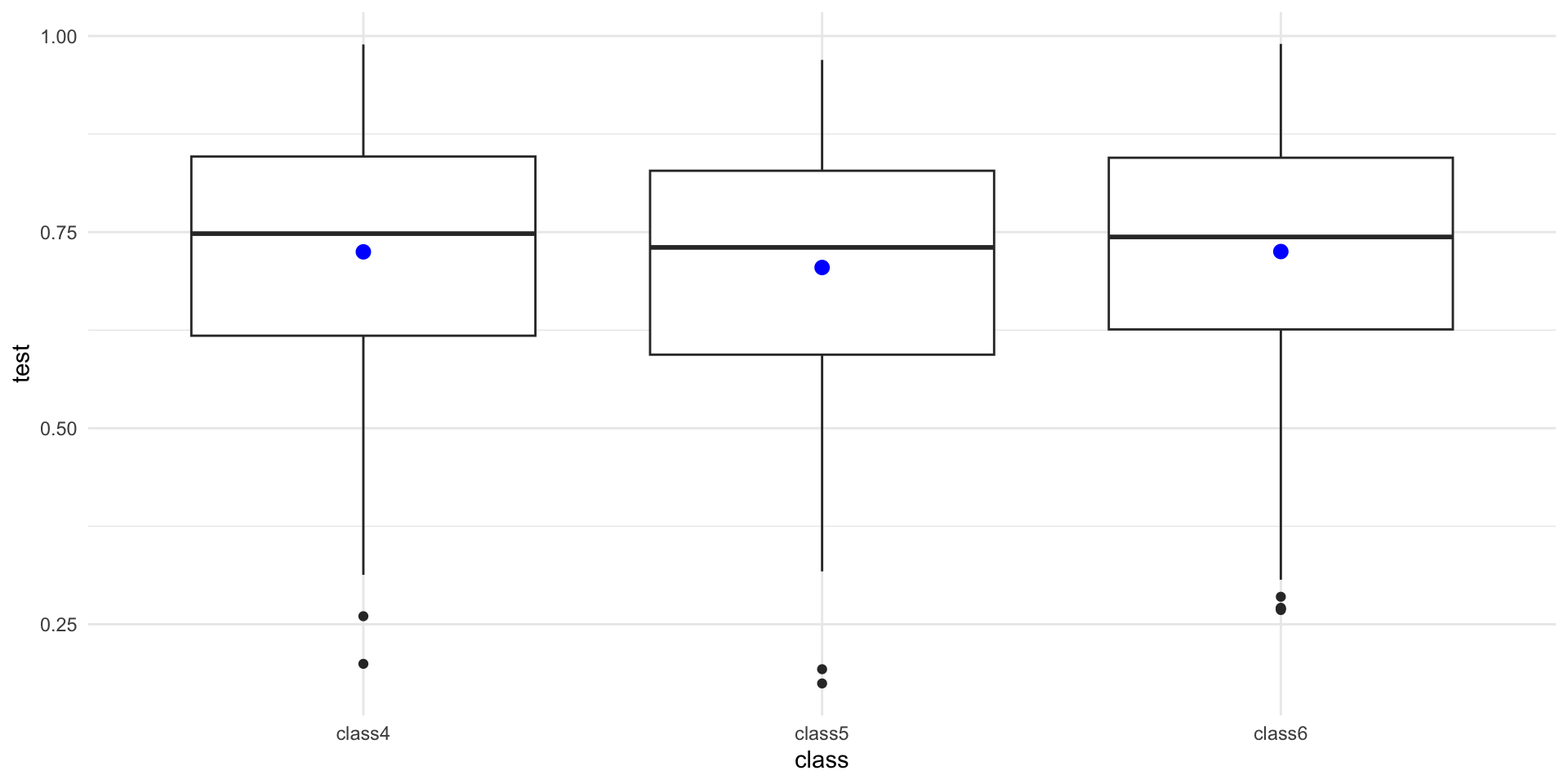
sample6 = sample(x = population, size = 322)| class | mean | SD |
|---|---|---|
| class4 | 0.72 | 0.15 |
| class5 | 0.70 | 0.16 |
| class6 | 0.73 | 0.15 |
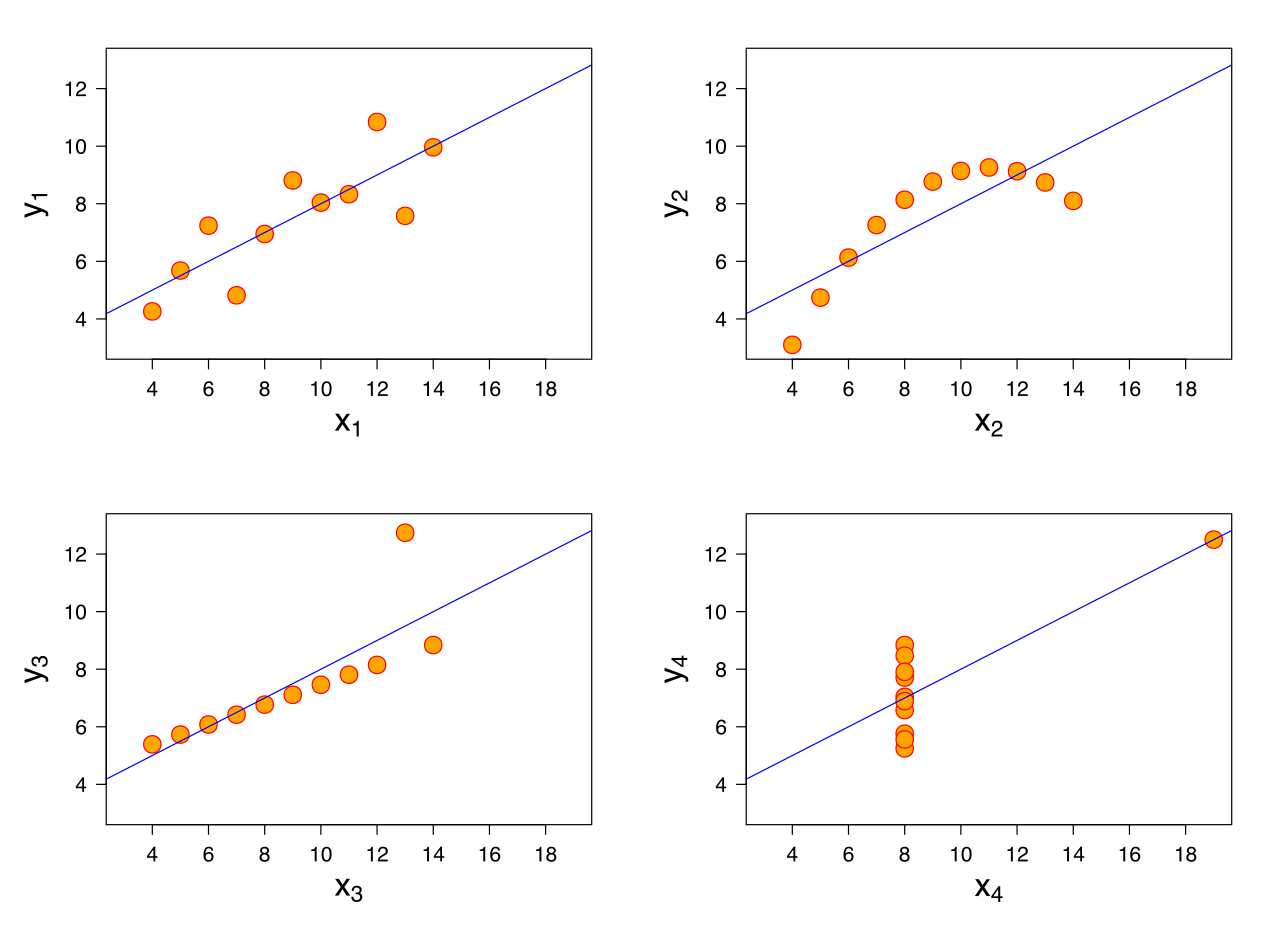
\(\bar{X}\) de x = 9
\(s\) de x = 3,3
\(\bar{X}\) de y = 7,5
\(s\) de y = 2
Corr de x e y = 0,816
Regressão linear: \(y = 3+0,5x\)
\(R^2=0,67\)