cambio | média | mediana | DP | n |
|---|---|---|---|---|
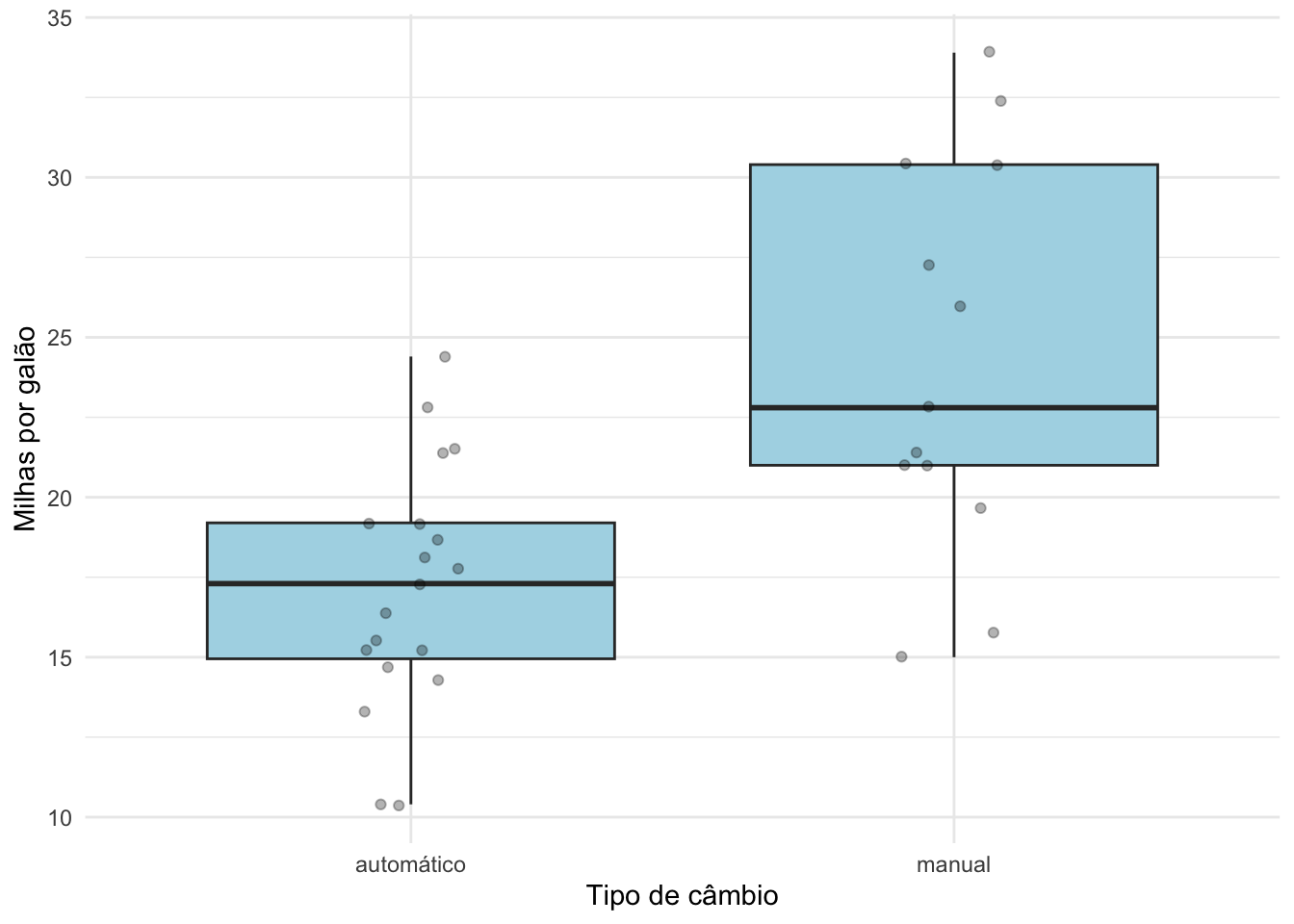
automático | 17.1 | 17.3 | 3.8 | 19 |
manual | 24.4 | 22.8 | 6.2 | 13 |
© 2026 Simbiose do Amanhã Consultoria Ltda., todos os direitos reservados
Este material está relacionado ao terceiro R da Jornada \(R^3\), o refinar. Depois de refletir sobre a sua análise e rodá-la no R, chega a parte de reportar os resultados. Para cada resultado, seja de estatística descritiva, testes estatísticos ou modelos de regressão, o pesquisador pode se valer de tabelas, gráficos, e descrição textual. Portanto, a seguir apresento um exemplo de como reportar resultados com esses três elementos, seguindo a ordem de estatística descritiva, testes estatísticos e modelos de regressão. Este material é disponibilizado em arquivo que possibilita facilmente copiar os modelos de texto e adaptar para o seus próprios dados e sua própria análise.
Primeiramente serão apresentados os códigos utilizados no R para gerar as tabelas, os gráficos e as análises em uma caixa de fundo cinza claro, que não devem ir para o texto (dissertação, tese, artigo), estão aqui apenas para que você saiba como foram gerados.
# Exemplo de bloco de códigos no R
Após os códigos, há uma seção com os resultados, mostrando as tabelas propriamente ditas, os gráficos e um texto que vem de exemplo para como reportar resultados, em uma caixa azul como esta seguir.
Você pode copiar o modelo de texto para adaptar aos seus resultados, mas tenha em mente que há diversas maneiras de redigir esse texto, sendo a ideia principal que você guie seu leitor na interpretação das tabelas e gráficos e chame a atenção para o que importa.
Apesar de apresentar os códigos para garantir reprodutibilidade das análises, este material não tem o objetivo de ser um guia, manual ou tutorial de análise quantitativa de dados, mas um guia de como reportar os resultados. Pressupõe-se, portanto, que o usuário deste material tem o conhecimento necessário sobre como conduzir as análises, utilizando este material como orientação para reportar os resultados.
Seguem algumas observações que se aplicam a praticamente todos os resultados.
Quando o valor de p é igual ou maior a \(0,001\), colocamos o símbolo de igual e o valor de p até a terceira casa decimal, por exemplo \(p = 0,068\). Quando ele é menor que 0,001, colocamos apenas \(p < 0,001\), sem colocar o valor exato.
Para não não deixar de reportar detalhes necessários e nem trazer uma falsa impressão de precisão com casas decimais a mais, a sugestão é seguir essas recomendações da APA (American Psychology Association) sobre a quantidade de casas decimais a serem reportadas:
< 0,001).O R separa decimais com pontos, mas ao escrevermos em português é importante usar vírgulas para separar os decimais, principalmente ao longo do texto.
Exemplo de como reportar médias, medianas e desvios-padrão, com os dados mtcars.
# Carregar pacotes
library(tidyverse)
library(flextable) # para gerar tabelas
# Carregar dados
data(mtcars)
# Mudar os rótulos de câmbio
mtcars = mtcars |>
mutate(cambio = ifelse(am == 0, "automático", "manual"))
# Dados descritivos
mtcars %>%
group_by(cambio) %>%
summarise(média = round(mean(mpg), 1),
mediana = median(mpg),
DP = round(sd(mpg), 1),
n = n()) |>
flextable()ggplot(mtcars, aes(x = cambio, y = mpg)) +
geom_boxplot(fill = "lightblue") +
geom_jitter(alpha = 0.3, width = 0.1) +
labs(y = "Milhas por galão", x = "Tipo de câmbio") +
theme_minimal()cambio | média | mediana | DP | n |
|---|---|---|---|---|
automático | 17.1 | 17.3 | 3.8 | 19 |
manual | 24.4 | 22.8 | 6.2 | 13 |
Exemplo com os dados mtcars.
# Carregar pacotes
library(tidyverse)
# Carregar dados
data(mtcars)
# gráfico
ggplot(mtcars, aes(x = am, y = mpg)) +
geom_boxplot(fill = "lightblue") +
geom_jitter(alpha = 0.3, width = 0.1) +
labs(y = "Milhas por galão", x = "Tipo de câmbio") +
theme_minimal()# Alterar rótulos da variável "câmbio"
mtcars = mtcars |>
mutate(cambio = ifelse(am == 0, "automático", "manual"))
# Teste t
t.test(data = mtcars, mpg ~ cambio)
Welch Two Sample t-test
data: mpg by cambio
t = -3.7671, df = 18.332, p-value = 0.001374
alternative hypothesis: true difference in means between group automático and group manual is not equal to 0
95 percent confidence interval:
-11.280194 -3.209684
sample estimates:
mean in group automático mean in group manual
17.14737 24.39231 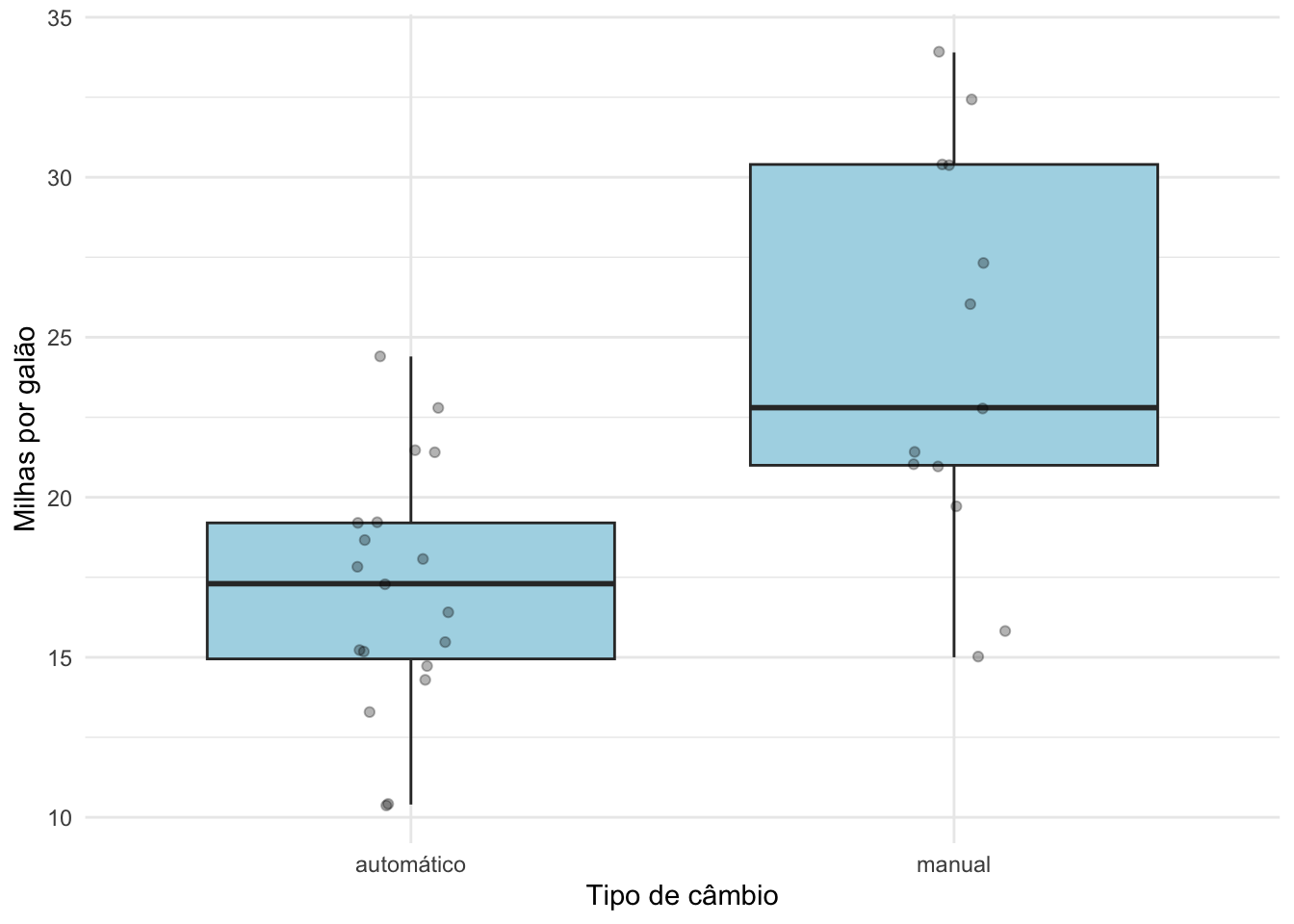
Ao longo do parágrado o resultado do teste t deve aparecer como t(graus de liberdade) = valor de t; valor de p. Note que, neste exemplo, colocamos \(p = 0,001\) porque de fato ele é igual a 0,001. Quando o valor de p é igual ou maior a 0,001, colocamos o símbolo de igual e o valor de p até a terceira casa decimal. Quando ele é menor que 0,001, colocamos apenas \(p < 0,001\), sem colocar o valor exato.
O ideal é que testes estatísticos sejam reportados juntamente com seus tamanhos de efeito. No caso deste exemplo, ficaria assim:
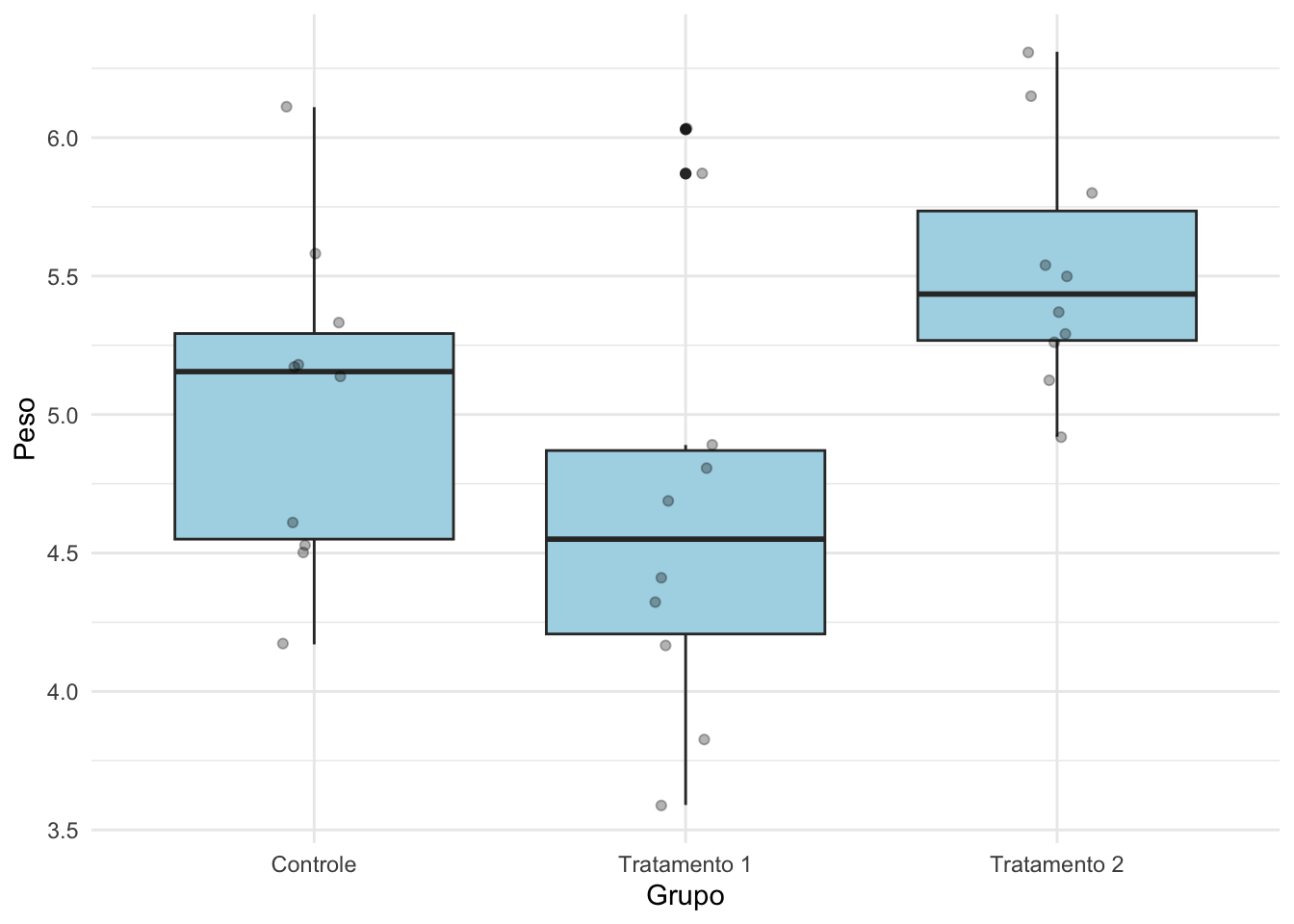
Exemplo com os dados PlantGrowth. Lembre-se que quando uma ANOVA com efeito significativo é reportada, é preciso reportar também os resultados dos testes pareados post-hoc.
# Carregar pacotes
library(tidyverse)
library(flextable) # para gerar tabelas
# Carregar dados
data(PlantGrowth)
# Mudar os rótulos dos grupos
PlantGrowth$grupo <- factor(PlantGrowth$group,
labels = c("Controle",
"Tratamento 1",
"Tratamento 2"))
# Dados descritivos
PlantGrowth %>%
group_by(grupo) %>%
summarise(média = round(mean(weight), 2),
mediana = round(median(weight), 2),
DP = round(sd(weight), 2),
n = n()) |>
flextable()ggplot(PlantGrowth, aes(x = grupo, y = weight)) +
geom_boxplot(fill = "lightblue") +
geom_jitter(alpha = 0.3, width = 0.1) +
labs(y = "Peso", x = "Grupo") +
theme_minimal()anova_plants <- aov(weight ~ grupo,
data = PlantGrowth)
summary(anova_plants) Df Sum Sq Mean Sq F value Pr(>F)
grupo 2 3.766 1.8832 4.846 0.0159 *
Residuals 27 10.492 0.3886
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1grupo | média | mediana | DP | n |
|---|---|---|---|---|
Controle | 5.03 | 5.15 | 0.58 | 10 |
Tratamento 1 | 4.66 | 4.55 | 0.79 | 10 |
Tratamento 2 | 5.53 | 5.44 | 0.44 | 10 |
Ao longo do parágrado o resultado da ANOVA deve aparecer como F(graus de liberdade) = valor de F; valor de p.
O ideal é que testes estatísticos sejam reportados juntamente com seus tamanhos de efeito. No caso deste exemplo, ficaria assim:
Como continuação da ANOVA realizada na seção anterior com os dados PlantGrowth.
# ANOVA:
anova_plants <- aov(weight ~ group,
data = PlantGrowth)
# Teste de Tukey
TukeyHSD(anova_plants) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = weight ~ group, data = PlantGrowth)
$group
diff lwr upr p adj
trt1-ctrl -0.371 -1.0622161 0.3202161 0.3908711
trt2-ctrl 0.494 -0.1972161 1.1852161 0.1979960
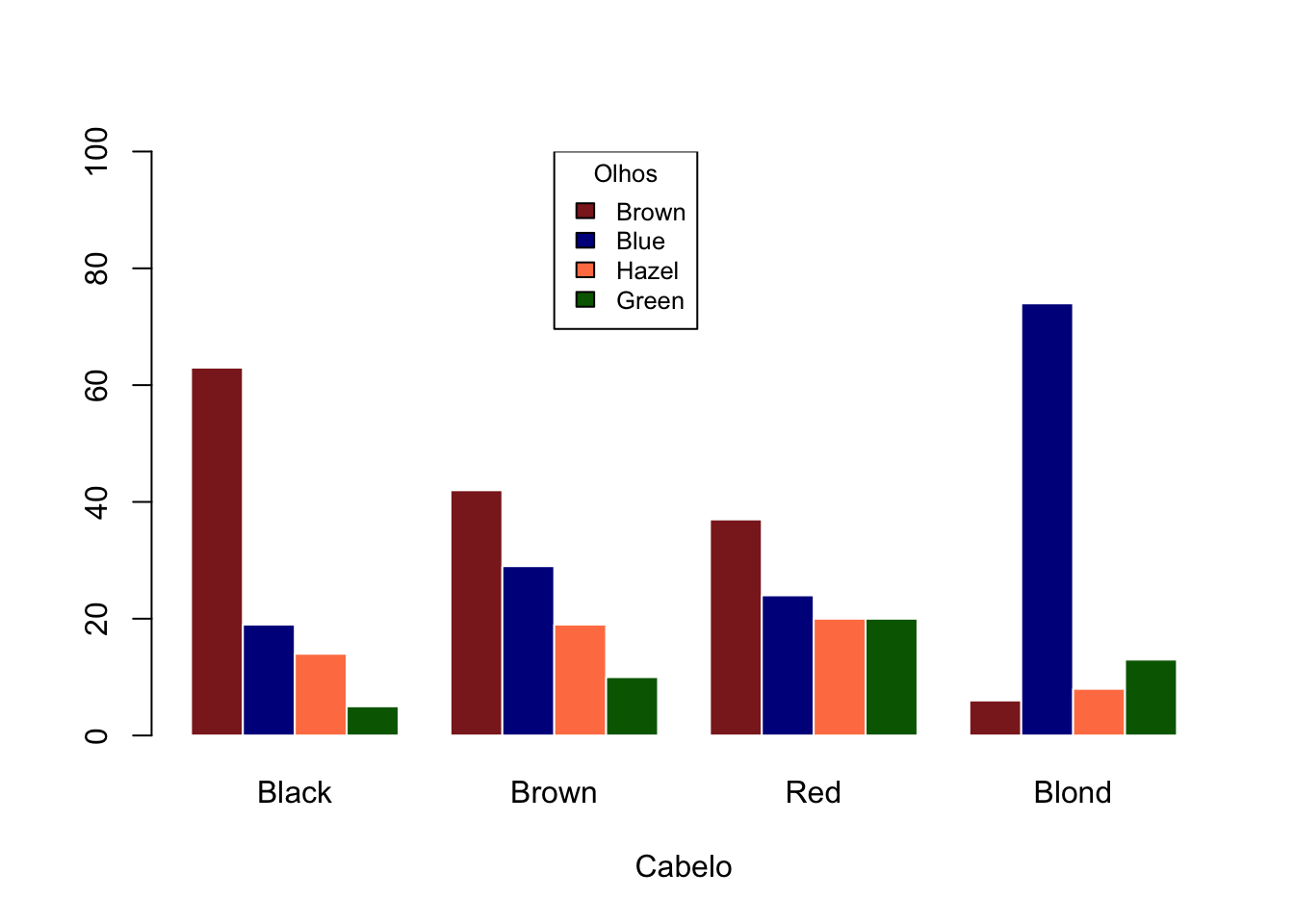
trt2-trt1 0.865 0.1737839 1.5562161 0.0120064Exemplo com os dados HairEyeColor.
# Carregar pacotes
library(flextable)
# Carregar dados
data(HairEyeColor)
# Tabela
tab2d <- margin.table(HairEyeColor, c(1, 2))
prop_row <- prop.table(tab2d, margin = 1)
df_row <- as.data.frame.matrix(prop_row)
df_row <- cbind(Hair = rownames(df_row), df_row)
rownames(df_row) <- NULL
df_row[ , -1] <- round(df_row[ , -1] * 100, 1)
ft <- flextable(df_row)
ft <- colformat_num(
ft,
j = 2:ncol(df_row),
digits = 1,
suffix = "%"
)
ft# Somar sexo masculino e feminino
hair_eye = margin.table(HairEyeColor, c(1,2))
# Tabela de proporções
propTable = round(prop.table(hair_eye, 1)*100)
# Invertendo o gráfico com transpose
propTable_T <- t(propTable)
barplot(propTable_T, beside = T,
ylim = c(0,100),
col = c("brown4", "darkblue", "coral", "darkgreen"),
border = "white",
xlab = "Cabelo")
legend(x=8, y=100, legend = c("Brown", "Blue", "Hazel", "Green"),
fill = c("brown4", "darkblue", "coral", "darkgreen"),
title = "Olhos")chisq.test(hair_eye)
Pearson's Chi-squared test
data: hair_eye
X-squared = 138.29, df = 9, p-value < 2.2e-16Hair | Brown | Blue | Hazel | Green |
|---|---|---|---|---|
Black | 63.0% | 18.5% | 13.9% | 4.6% |
Brown | 41.6% | 29.4% | 18.9% | 10.1% |
Red | 36.6% | 23.9% | 19.7% | 19.7% |
Blond | 5.5% | 74.0% | 7.9% | 12.6% |
Ao longo do parágrado o resultado do qui-quadrado deve aparecer como \(\chi^2\)(graus de liberdade) = valor do qui-quadrado; valor de p.
O ideal é que testes estatísticos sejam reportados juntamente com seus tamanhos de efeito. No caso deste exemplo, ficaria assim:
Exemplo com os dados mtcars.
ggplot(mtcars, aes(y = mpg, x = wt)) +
geom_point() +
geom_smooth(method = lm) +
labs(x = "Peso", y = "Autonomia (mpg)") +
theme_minimal()cor.test(mtcars$mpg, mtcars$wt)
Pearson's product-moment correlation
data: mtcars$mpg and mtcars$wt
t = -9.559, df = 30, p-value = 1.294e-10
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9338264 -0.7440872
sample estimates:
cor
-0.8676594 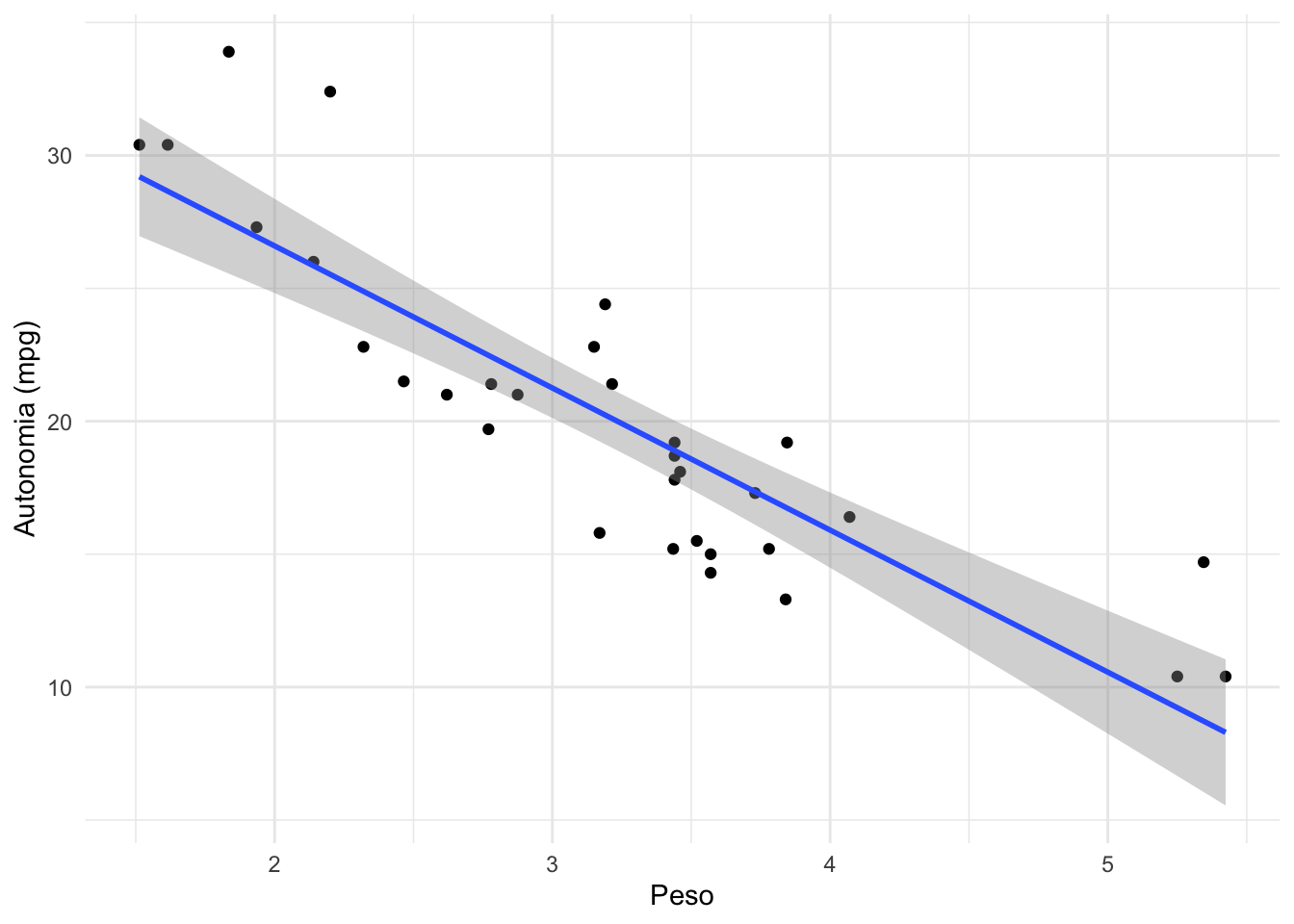
Ao longo do parágrado o resultado do qui-quadrado deve aparecer como r(graus de liberdade) = valor do coeficiente de correlação; IC95% [intervalo de confiança]; valor de p.
Para reportar testes não paramétricos, os princípios são os mesmos de suas contra-partes paramétricas, alterando apenas a letra da estatística resultante, e omitindo os graus de liberdade quando não há.
Por exemplo:
wilcox.test(mpg ~ cambio, data = mtcars)
Wilcoxon rank sum test with continuity correction
data: mpg by cambio
W = 42, p-value = 0.001871
alternative hypothesis: true location shift is not equal to 0kruskal.test(data = PlantGrowth, weight ~ group)
Kruskal-Wallis rank sum test
data: weight by group
Kruskal-Wallis chi-squared = 7.9882, df = 2, p-value = 0.01842cor.test(mtcars$mpg, mtcars$wt, method = "spearman")
Spearman's rank correlation rho
data: mtcars$mpg and mtcars$wt
S = 10292, p-value = 1.488e-11
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
-0.886422 # Mudar os rótulos de câmbio
mtcars = mtcars |>
mutate(cambio = ifelse(am == 0, "automático", "manual"))
# Modelo
modelo = lm(data = mtcars, mpg ~ cambio)library(sjPlot)
tab_model(modelo)library(sjPlot)
plot_model(modelo, type = "pred") +
labs(title = "", y = "Autonomia prevista (mpg)", x = "Tipo de câmbio") +
theme_minimal()| mpg | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 17.15 | 14.85 – 19.44 | <0.001 |
| cambio [manual] | 7.24 | 3.64 – 10.85 | <0.001 |
| Observations | 32 | ||
| R2 / R2 adjusted | 0.360 / 0.338 | ||
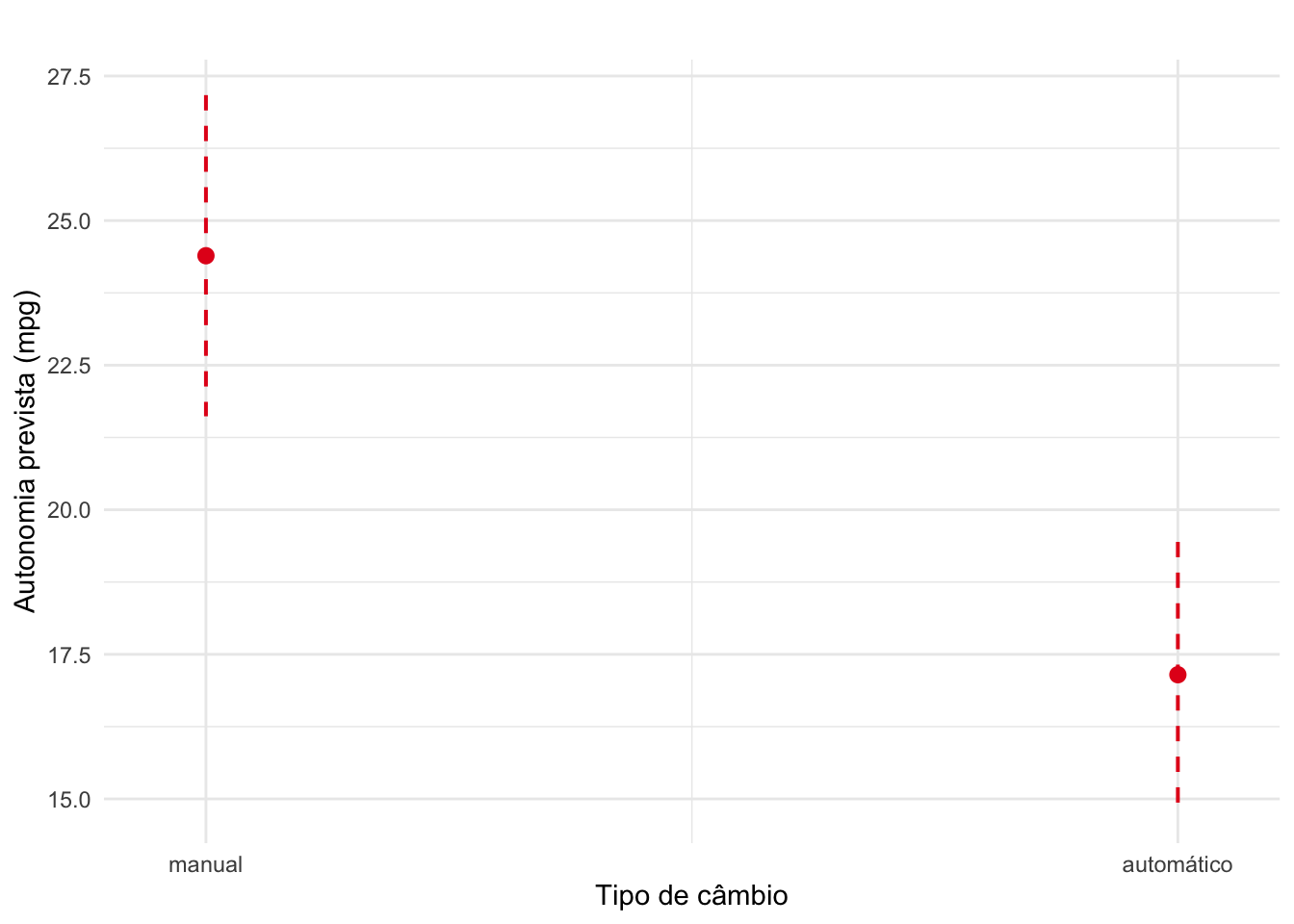
Ao longo do parágrado o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para a variável preditora.
É importante, ao reportar modelos de regressão, que o texto guie o leitor na leitura das tabelas e dos gráficos, pensando que pode haver leitores não familiarizados com modelos de regressão e que precisarão de explicações voltadas para as variáveis utilizadas.
# Carregar pacotes
library(tidyverse)
# Carregar dados
data(mtcars)
modelo = lm(data = mtcars, mpg ~ wt)library(sjPlot)
tab_model(modelo)library(sjPlot)
plot_model(modelo, type = "pred") +
labs(title = "", y = "Autonomia prevista (mpg)", x = "Peso") +
theme_minimal()| mpg | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 37.29 | 33.45 – 41.12 | <0.001 |
| wt | -5.34 | -6.49 – -4.20 | <0.001 |
| Observations | 32 | ||
| R2 / R2 adjusted | 0.753 / 0.745 | ||
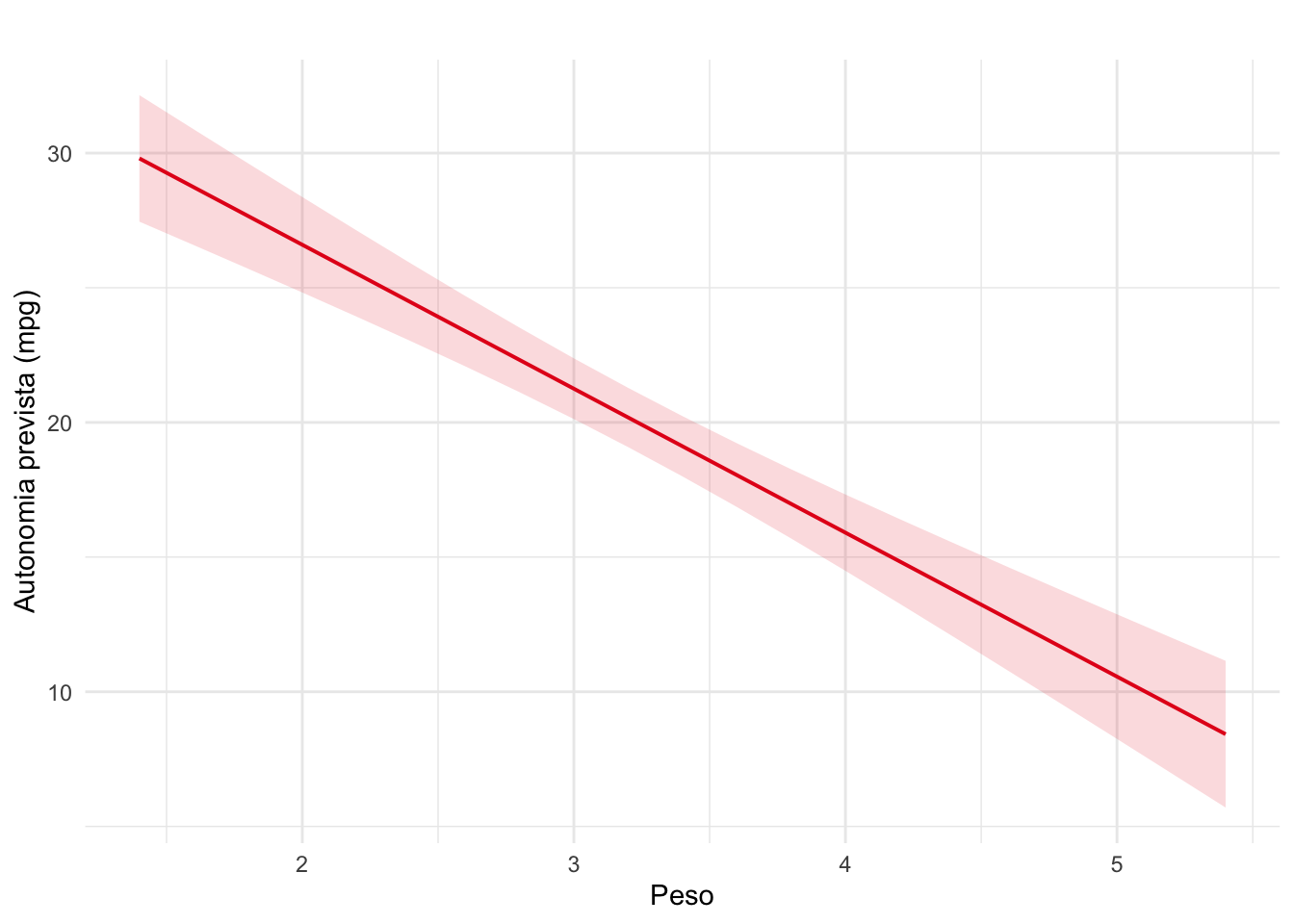
Ao longo do parágrado o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para a variável preditora.
É importante, ao reportar modelos de regressão, que o texto guie o leitor na leitura das tabelas e dos gráficos, pensando que pode haver leitores não familiarizados com modelos de regressão e que precisarão de explicações voltadas para as variáveis utilizadas.
# Carregar pacotes
library(tidyverse)
# Carregar dados
data(mtcars)
# Mudar os rótulos de câmbio e de motor
mtcars = mtcars |>
mutate(cambio = ifelse(am == 0, "automático", "manual")) |>
mutate(motor = ifelse(vs == 0, "V", "reto"))
# Modelo
modelo = lm(data = mtcars, mpg ~ cambio + wt + motor)library(sjPlot)
tab_model(modelo)library(sjPlot)
plot_model(modelo, type = "pred") +
labs(title = "", y = "Autonomia prevista (mpg)", x = "Peso") +
theme_minimal()| mpg | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 33.69 | 27.50 – 39.89 | <0.001 |
| cambio [manual] | 1.49 | -1.55 – 4.54 | 0.324 |
| wt | -3.78 | -5.62 – -1.94 | <0.001 |
| motor [V] | -3.62 | -6.23 – -1.00 | 0.008 |
| Observations | 32 | ||
| R2 / R2 adjusted | 0.808 / 0.787 | ||
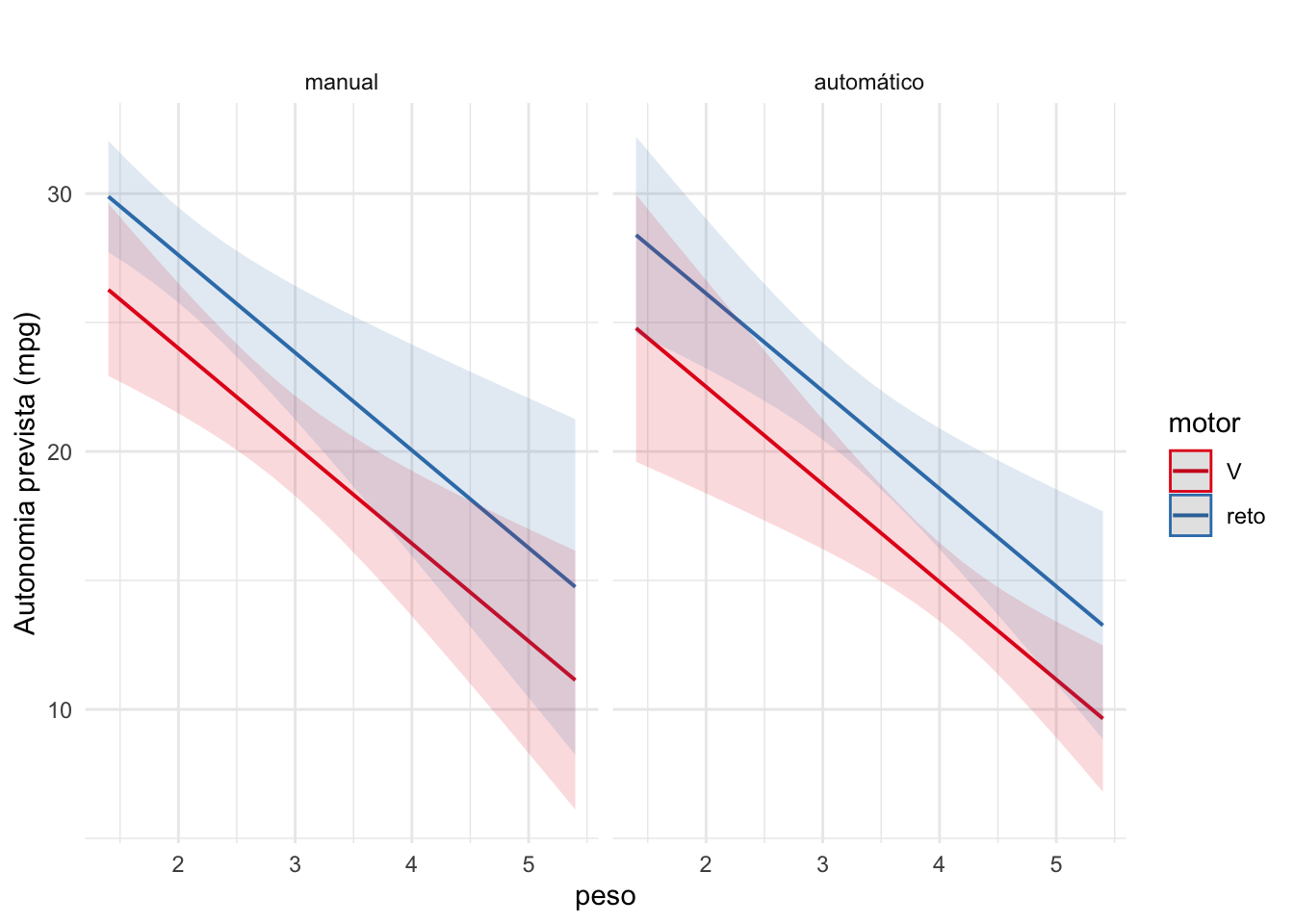
Ao longo do parágrado o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para as variáveis preditoras.
Ao reportar modelo múltiplos, principalmente aqueles com muitas variáveis preditoras, é importante guiar o leitor na leitura da tabela e dos gráficos chamando atenção para os efeitos que mais relevantes, que, muitas vezes, podem o ser não pelos resultados, mas também pelo papel que eles têm na pesquisa como um todo.
# Carregar pacotes
library(tidyverse)
# Carregar dados
data(mtcars)
# Modelo
modelo <- glm(am ~ mpg + wt + hp,
data = mtcars,
family = binomial)library(sjPlot)
tab_model(modelo) # resultado em odds ratios
tab_model(modelo, transform - NULL) # resultado em log-oddslibrary(sjPlot)
plot_model(modelo, type = "pred") +
labs(title = "", y = "Autonomia prevista (mpg)", x = "Peso") +
theme_minimal()Modelos de regressão logística impõem um desafio ao reportar os resultados porque os coeficientes são dados no log das chances (log-odds), que podem ser transformados em razão das chances (odds ratios), porém com a expectativa intuitiva da maioria dos leitores de interpretar as probabilidades. Por isso, é preciso prmeiramente decidir se vai reportar os resultados em log-odds ou odds ratios e, em qualquer um dos casos, explicar para o seu leitor como interpretar, trazendo probabilidades sempre que possível, principalmente no gráfico de valores (probabilidades) previstos pelo modelo.
| am | |||
|---|---|---|---|
| Predictors | Odds Ratios | CI | p |
| (Intercept) | 0.00 | 0.00 – 0.00 | 0.026 |
| mpg | 3.52 | 1.61 – 15.97 | 0.026 |
| hp | 1.06 | 1.02 – 1.13 | 0.041 |
| Observations | 32 | ||
| R2 Tjur | 0.578 | ||
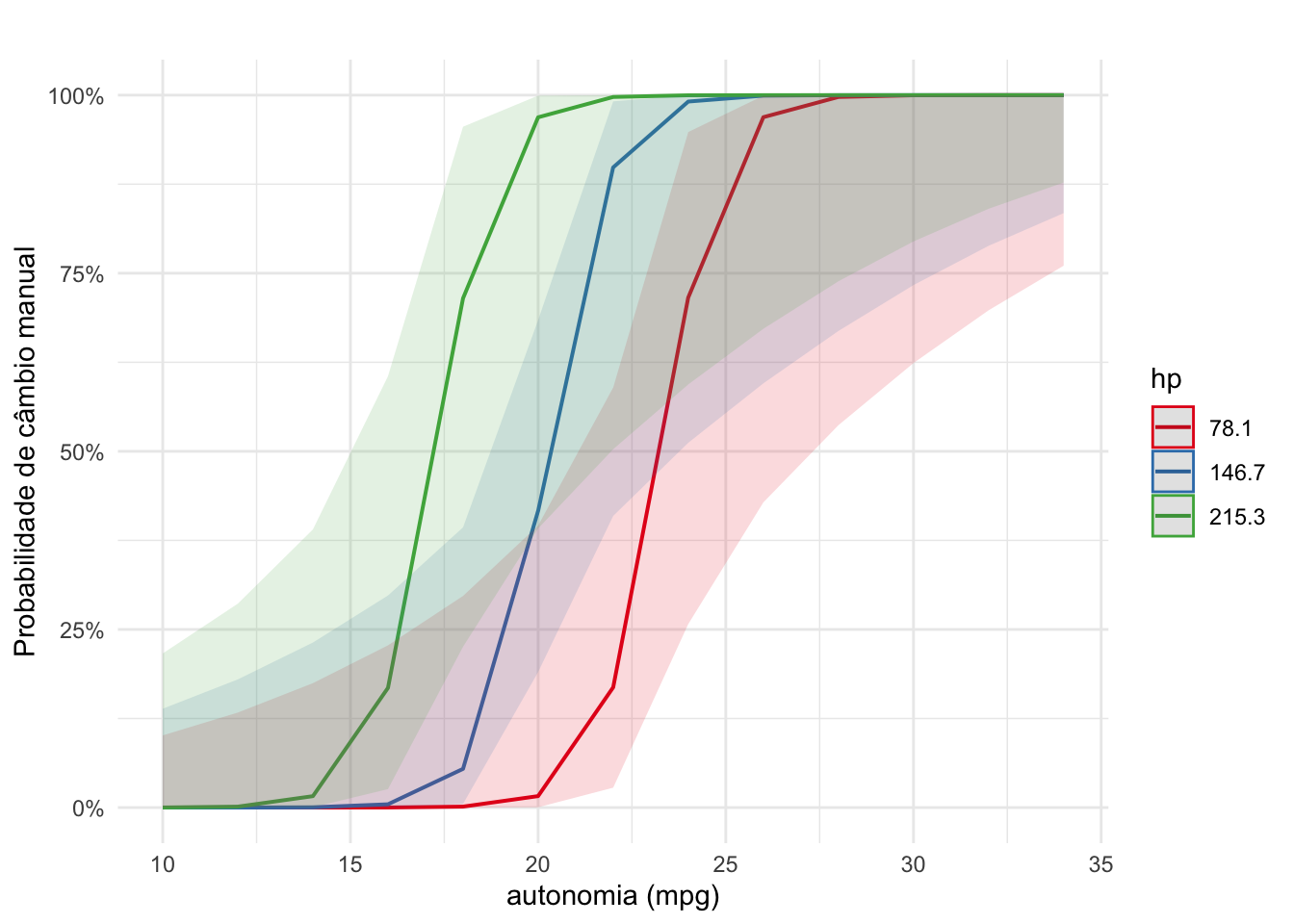
Ao longo do parágrado o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para as variáveis preditoras.
É importante, ao reportar modelos de regressão logística com odds ratios, presumir que nem todos os leitores serão familiarizados com chances, e, por isso, ao longo do parágrafo vale explicar como cada coeficiente afeta os aumentos ou reduções das chances, principalmente das que foram significativas.
| am | |||
|---|---|---|---|
| Predictors | Log-Odds | CI | p |
| (Intercept) | -33.61 | -73.64 – -12.66 | 0.026 |
| mpg | 1.26 | 0.47 – 2.77 | 0.026 |
| hp | 0.06 | 0.02 – 0.13 | 0.041 |
| Observations | 32 | ||
| R2 Tjur | 0.578 | ||
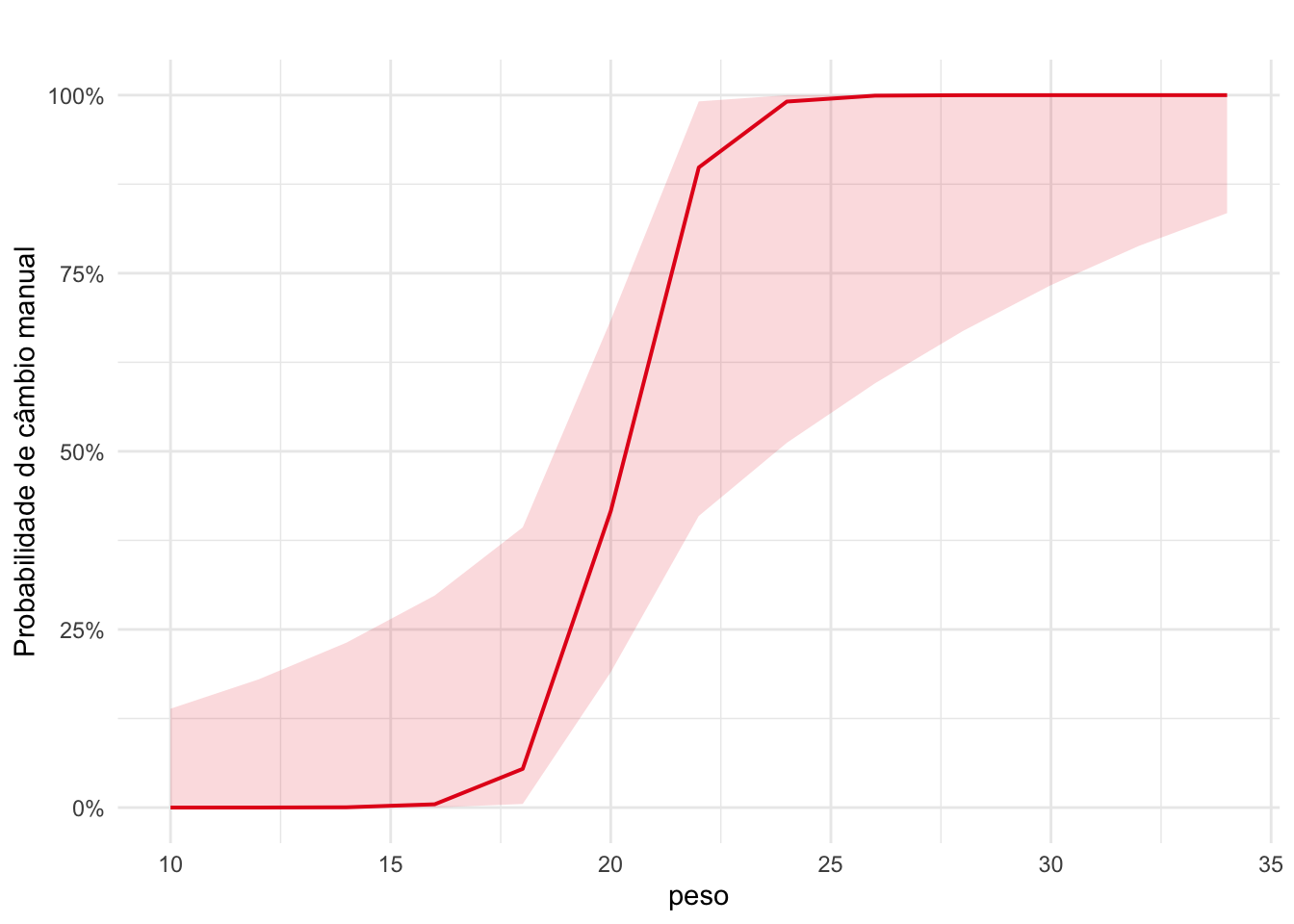
Ao longo do parágrado o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para as variáveis preditoras.
É importante, ao reportar modelos de regressão logística com log-odds, presumir que nem todos os leitores serão familiarizados com chances, muito menos com o log das chances, e, por isso, ao longo do parágrafo é bom explicar como cada coeficiente afeta os aumentos ou diminuições das chances, principalmente das que foram significativas.
# Carregar pacotes
library(tidyverse)
library(lme4)
# Carregar dados
data(sleepstudy)
# Modelo
modelo <- lmer(Reaction ~ Days + (Days | Subject), data = sleepstudy)library(sjPlot)
tab_model(modelo)library(sjPlot)
plot_model(modelo, type = "pred") +
labs(title = "", y = "Tempo de reação prevista", x = "Dias sem dormir") +
theme_minimal()| Reaction | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 251.41 | 237.94 – 264.87 | <0.001 |
| Days | 10.47 | 7.42 – 13.52 | <0.001 |
| Random Effects | |||
| σ2 | 654.94 | ||
| τ00 Subject | 612.10 | ||
| τ11 Subject.Days | 35.07 | ||
| ρ01 Subject | 0.07 | ||
| ICC | 0.72 | ||
| N Subject | 18 | ||
| Observations | 180 | ||
| Marginal R2 / Conditional R2 | 0.279 / 0.799 | ||
Ao se ajustar um modelo de regressão com efeitos aleatório/mistos, normalmente a pesquisa continua interessada nos efeitos fixos, porém acrescenta os efeitos aleatórios para informar o modelo sobre a dependência de dados repetidos. Sendo assim, o texto sobre os resultados pode ser como nos demais modelos, podendo acrescentar um comentário sobre os efeitos aleatórios ao final.
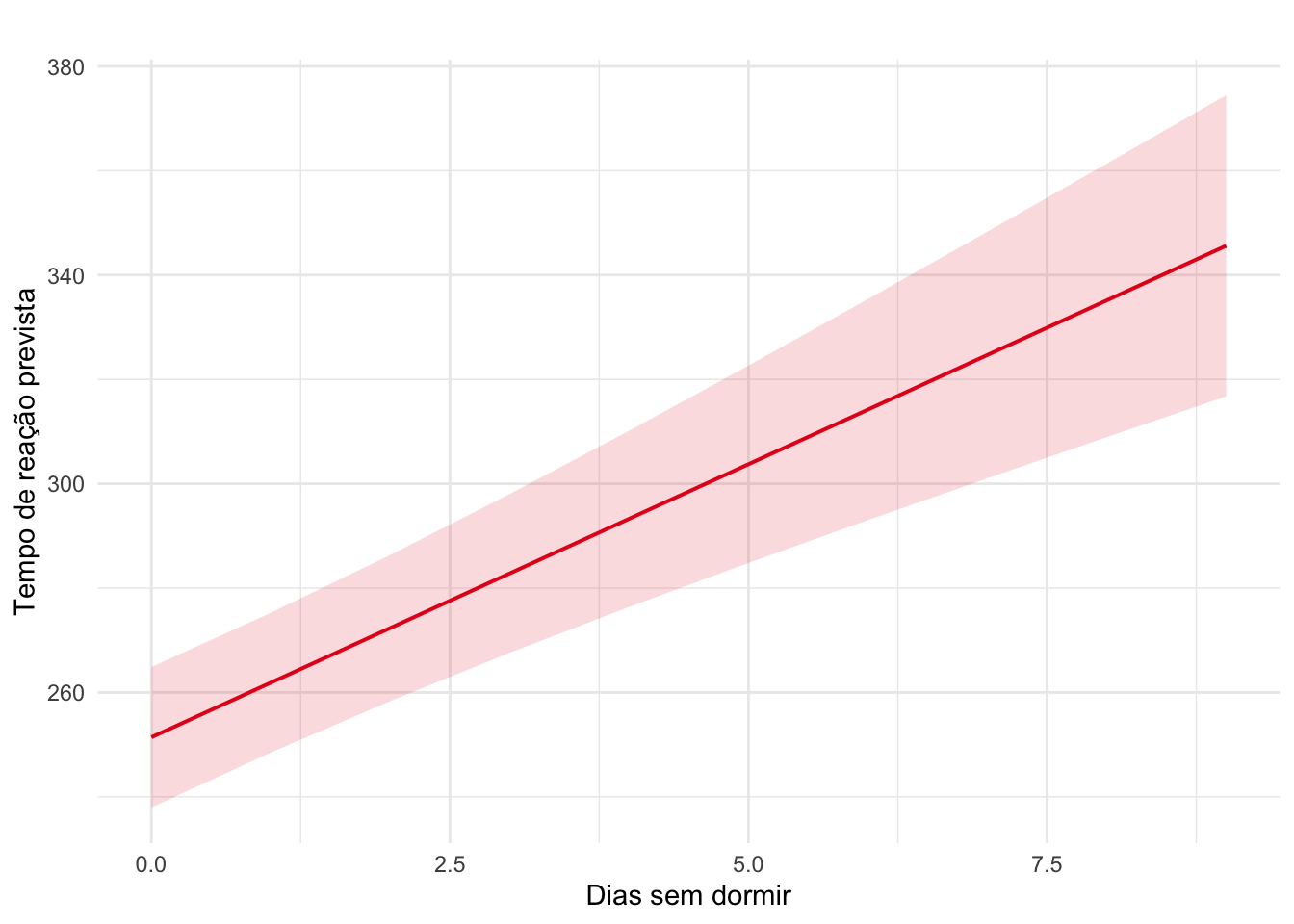
Assim como nos demais modelos de regressão, ao longo do parágrafo o resultado do modelo de regressão pode aparecer como \(\beta\) = valor do coeficiente; IC95% [intervalo de confiança]; valor de p para as variáveis preditoras.
Caso o não tenha sido possível incluir inclinaçãointercepto e inclinação aleatórios no seu modelo por aviso de singular fit ou por falta de convergência do modelo, informe isso no seu parágrafo para que o leitor entenda o motivo da simplificação do modelo.
Para os demais modelos de regressão (e.g., ordinal, poisson, multinomial, etc.) seguem-se os mesmos princípios, sempre guiando o leitor em compreender os coeficientes das tabelas e fazendo referência aos valores previstos pelo modelo por meio de gráficos.