3 Segundo exemplo
O segundo exemplo se aproxima do aconselhável, que é uma análise utilizando um modelo de regressão. Os dados utilizados aqui são bastante simples, e não permitem a inclusão de interação e de efeitos mistos, o que pode ser feito na análise de vocês.
As seções 1 e 2 são muiot similares ao exemplo 1, com pequenas inclusões. Veja, contudo, a diferença nas perguntas e hipóteses, que envolvem questões que modelos de regressão dão conta e que testes estatísticos não.
3.1 Explicação dos dados
Os dados utilizados nesta análise são dados das sete vogais orais tônicas do português do Brasil, coletadas por meio da gravação de palavras-alvo inseridas em frases-veículo lidas por um falante de São Paulo. As palavras eram dissílabas, paroxítonas, com a estrutura CV.CV; e a frase-guia utilizada foi “Digo palavra baixinho.” Há 234 observações, entre 11 e 43 observações para cada vogal, e as variáveis são ‘duração’ (em milissegundos) e valor do primeiro formante (F1, em Hertz). A Tabela 3.1 apresenta a quantidade de observações por vogal.
| Vogal | Observações |
|---|---|
| a | 34 |
| e | 38 |
| ɛ | 27 |
| i | 38 |
| o | 11 |
| ɔ | 41 |
| u | 43 |
As perguntas de pesquisa são:
- Qual é o efeito de vogal sobre suas durações?
- Qual é o efeito do F1 sobre a duração das vogais?
As hiopóteses são:
- A altura das vogais é inversamente proporcional à duração, com vogais mais altas apresentam duração mais baixa e vice-versa.
- Há uma associação positiva entre duração e F1 das vogais – quanto mais aumenta o valor de um correlato, mais aumento o valor do outro.
3.2 Análise exploratória dos dados
A tabela 3.1 apresenta as médias, medianas e desvios-padrão da duração (em milissegundos) do primeiro formante (em Hertz) das vogais analisadas.
Figure 3.1: Dados descritivos: média, mediana e desvio-padrão da duração e de F1 por vogal
A menor média de duração foi da vogal /i/, com 87ms, seguida da vogal /u/, com média de 89ms. Esse resultado está alinhado com a literatura, já que vogais altas tendem a ser mais breves do que vogais baixas. A maior média de duração foi da vogal /o/ seguida da vogal /a/, com 119 e 111 milissegundos respectivamente.
O gráfico de caixas 3.2 e 3.3 a seguir apresenta as vogais em ordem crescente das medianas de duração.
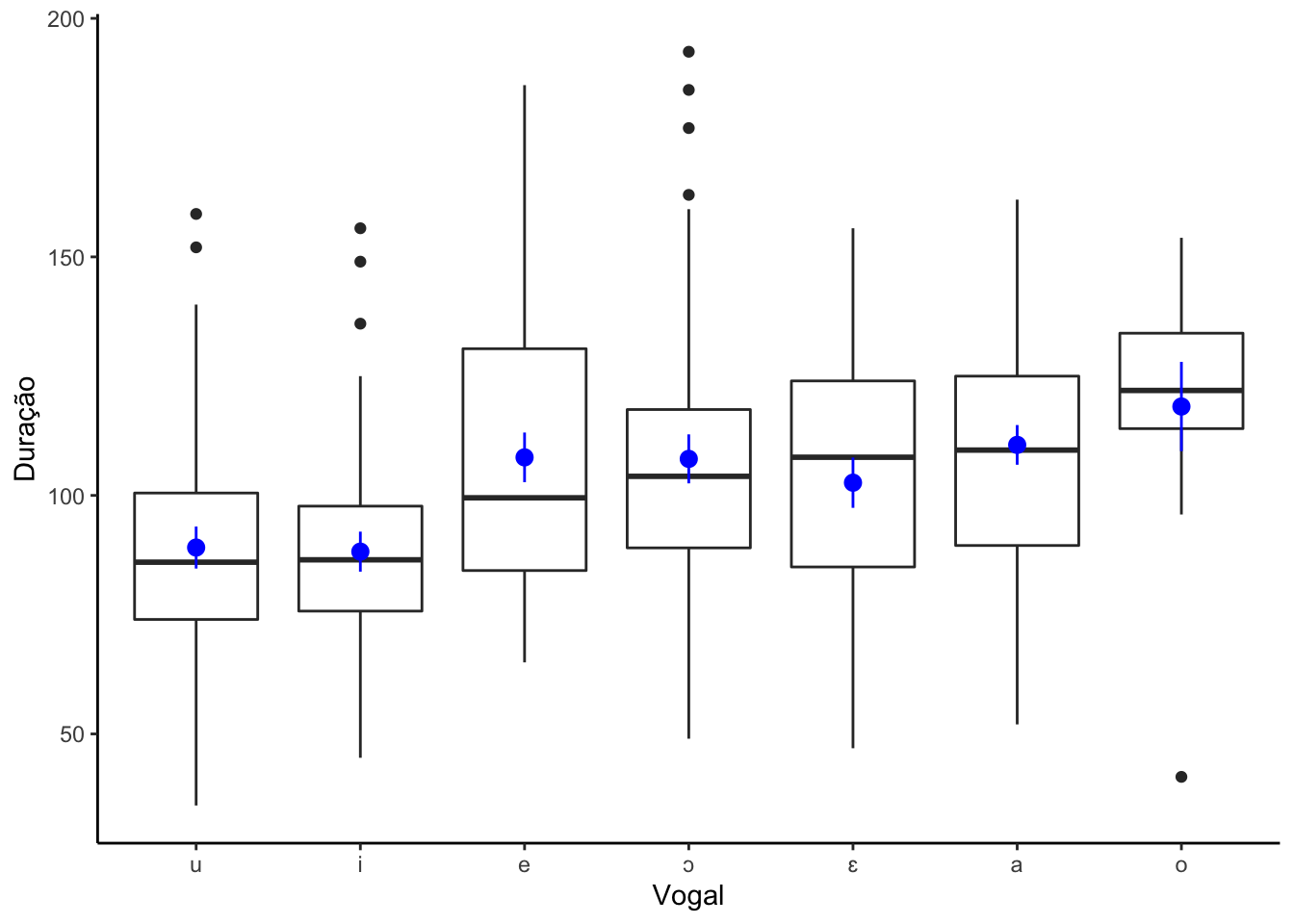
Figure 3.2: Gráficos de caixas com duração por vogal
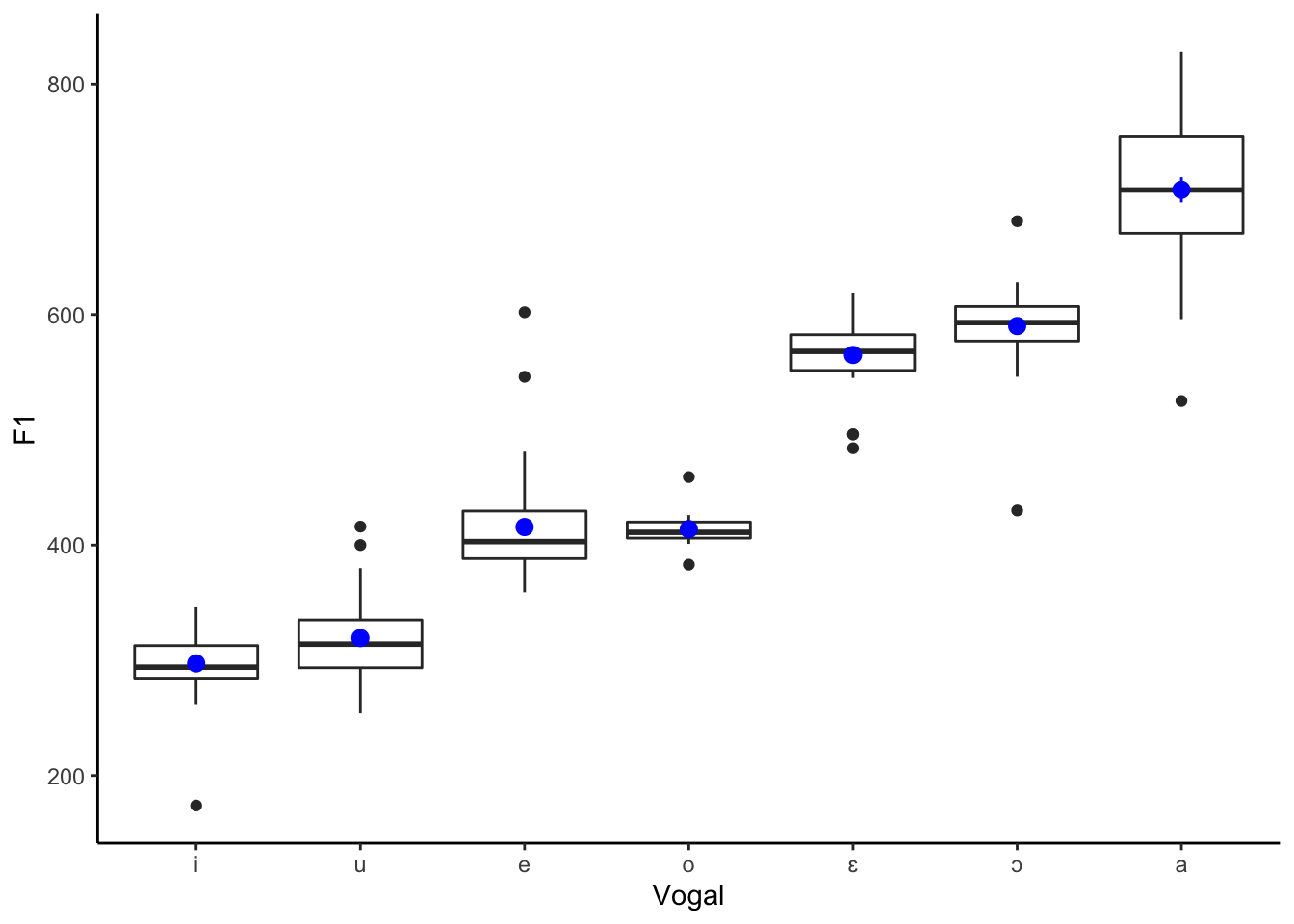
Figure 3.3: Gráfico de caixas com valores de F1 por vogal
O primeiro formante (F1) é um correlato acústico que correponde à altura da língua, com vogais mais altas exibindo valores menores de F1, e vogais mais baixas apresentando valores mais altos de F1. Os dados analisados apresentaram essa tendência, com as vogais altas /i/ e /u/ apresentando os menos valores de F1, e a vogal baixa /a/ apresentando os valores mais altos.
O gráfico 3.4 apresenta as vogais em função dos valores de F1, em ordem crescente dos valores de F1. Com a plotagem é possível verificar que há dois erros de medição no F1 da vogal /i/, umas vez que valores acima de 900 Hz para F1 não são possíveis. Sendo assim, esses dois dados foram excluídos de toda a análise que segue. O gréfico de caixas seguinte apresenta os dados sem esses dois dados.
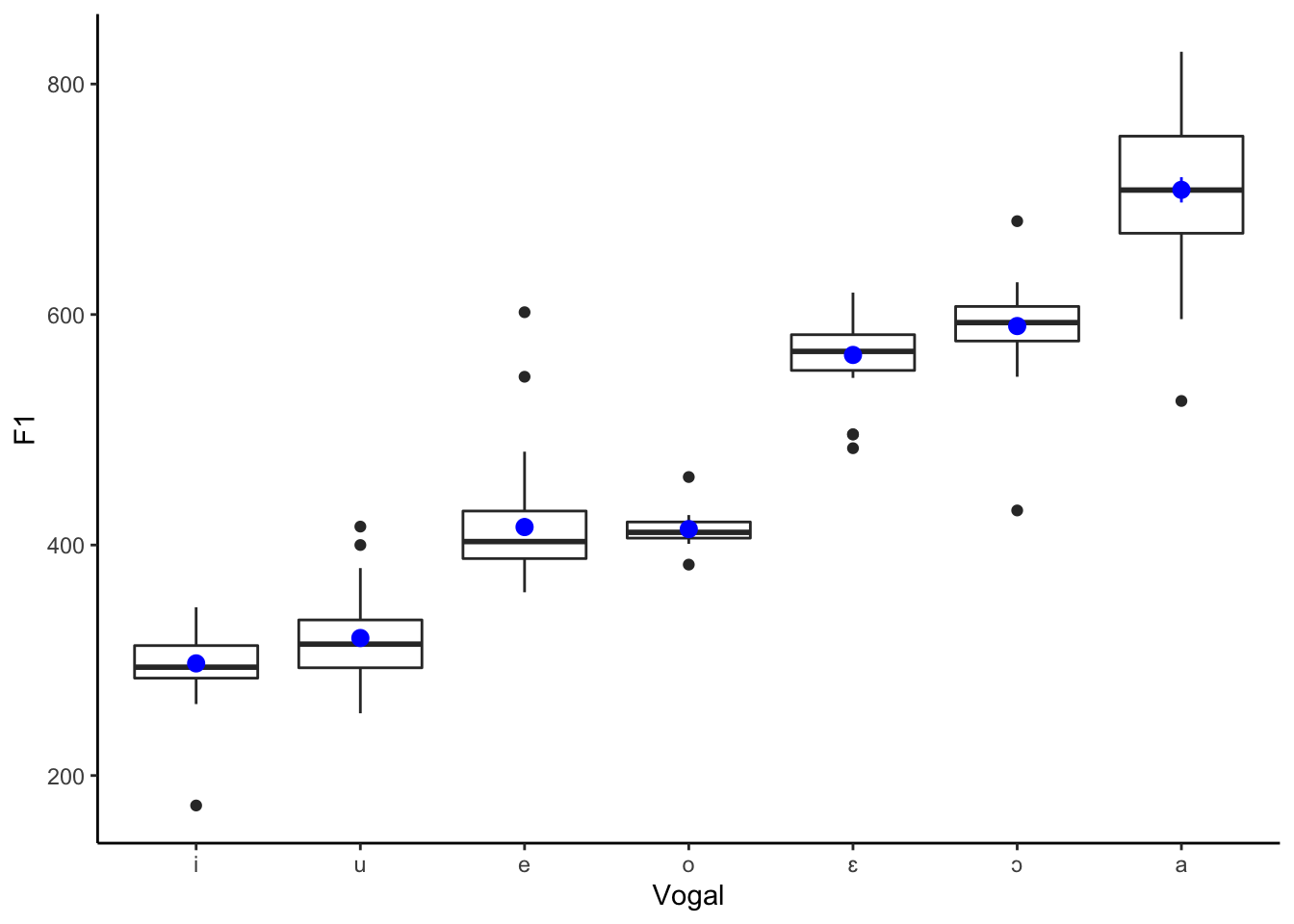
Figure 3.4: Gráfico de caixas de F1 por vogal sem os dados extremos (erros de medição)
Por fim, o gráfico de dispersão (scatter plto) 3.5 apresenta a associação positiva entre duração e F1: quanto mais aumenta a duração, mais aumenta o valor de F1 e vice-versa.
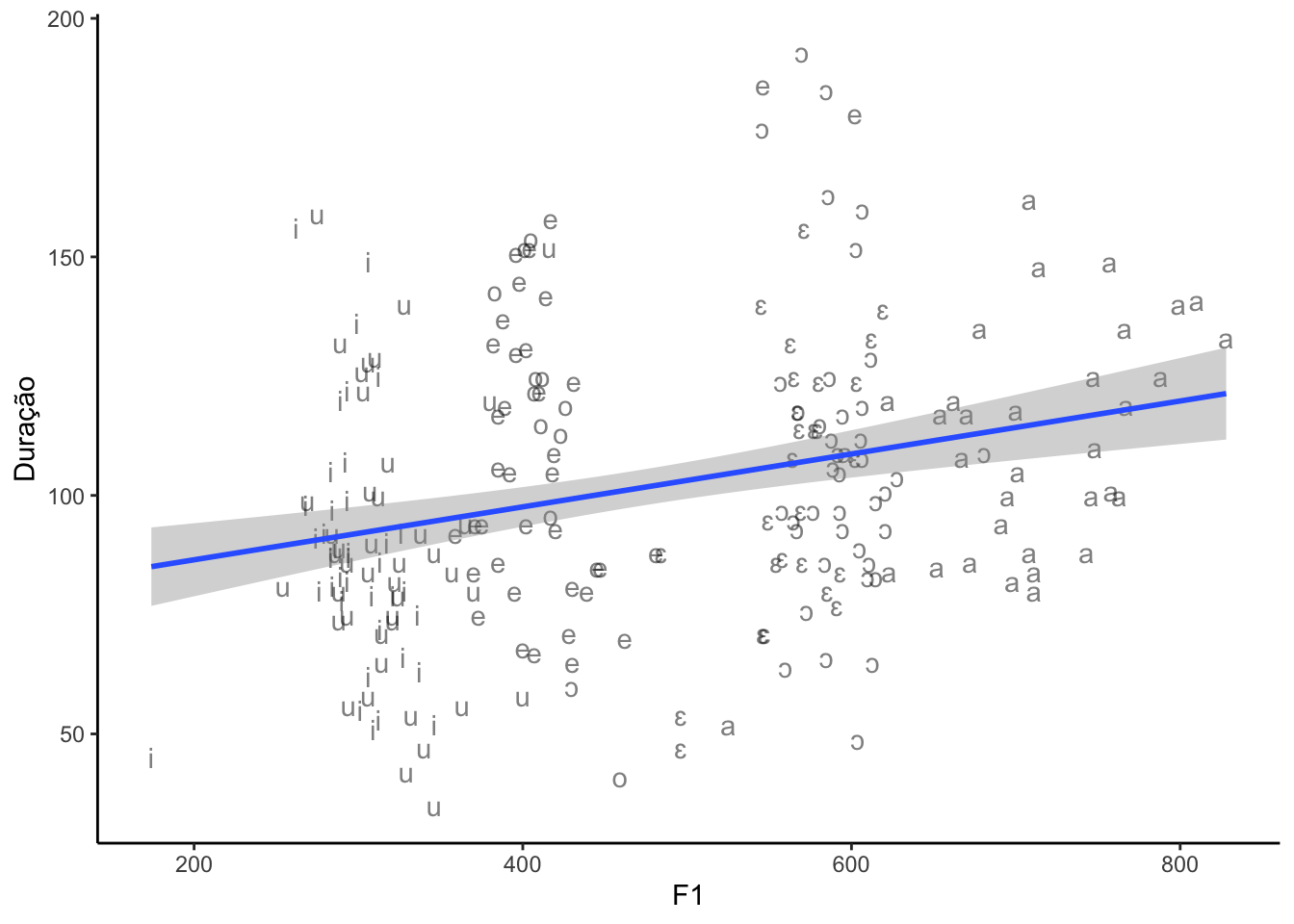
Figure 3.5: Gráfico de dispersão de duração e F1
Dica: Para adicionar as vogais (em vez dos pontos) no gráfico, basta utilizar geom_text(aes(label = vogal), alpha = 0.5) no lugar de geom_point().
3.3 Análise inferencial dos dados
Para a análise inferencial foi ajustado um modelo de regressão linear multifatorial com duração em função do F1 e da vogal.
(Trata-se de um exemplo didático, a fim de demosntrar um modelo de regressão múltipla com dados simples; porém, em uma análise real não faria sentido incluir tanto vogal como F1 como variáveis preditoras por serem multicolineares – a informação de F1 está presente em vogal também)
A tabela a seguir apresenta os coeficientes do modelo, com seus intervalos de confiança e valores de p.
| dur | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 18.93 | -46.93 – 84.78 | 0.572 |
| F1 | 0.13 | 0.04 – 0.22 | 0.006 |
| vogal [e] | 35.25 | 5.23 – 65.28 | 0.022 |
| vogal [ɛ] | 10.62 | -9.00 – 30.24 | 0.287 |
| vogal [i] | 30.80 | -9.27 – 70.87 | 0.131 |
| vogal [o] | 46.15 | 12.75 – 79.55 | 0.007 |
| vogal [ɔ] | 12.37 | -4.64 – 29.37 | 0.153 |
| vogal [u] | 28.81 | -9.23 – 66.85 | 0.137 |
| Observations | 232 | ||
| R2 / R2 adjusted | 0.136 / 0.109 | ||
Como pode ser visto, há efeito significativo para F1, com cada Hert de aumento em F1 aumentando a duração em 0,13 milissegundos. A vogal de referência é /a/, e mudá-la para /e/ epara /o/ também acarreta em mudança significartiva na duraçã, com aumento de 33 e 46 milissegundos, respectivamente. O valor de \(R^2\), contudo, apresenta baixo poder explicativo do modelo, com apenas 11% da variação em duração explicada por F1 e vogal.